Blogs | Jared Knowleshttps://jaredknowles.com/posts/2026-06-12T01:05:45ZData analysis, photography, and the occasional thought.Jared E. Knowlesjared@fastmail.usmerTools 1.0: prediction intervals for mixed models, validated against brmshttps://jaredknowles.com/posts/mertools-1-0-released/2026-05-30T11:44:41Z2026-05-30T11:44:41ZAfter a decade on CRAN, merTools 1.0.0 is out today. It has been a long-term goal of mine to bring merTools to a stable state, fix outstanding bugs, and rework the `predictInterval()` function at its core to be more modular and easy to maintain. This release achieves that and marks the package as feature complete and the start of a long-term-support (LTS) phase. This release hits the goal of 1.0.0 of a stable API, outstanding issues closed, a correctness fix at the core of predictInterval(), and modularity in the core prediction interval functionality. The documentation is also now available [via a pkgdown site as well!](https://jknowles.github.io/merTools) install.packages("merTools") (post.css styles
p.dropcap::first-letter). goldmark does NOT parse markdown inside a raw
HTML block, so bold/italic/code/links here are hand-written as HTML. -->
After a decade on CRAN, merTools 1.0.0 is out today.
It has been a long-term goal of mine to bring merTools to a stable state, fix outstanding bugs,
and rework the `predictInterval()` function at its core to be more modular and easy to maintain.
This release achieves that and marks the package as feature complete and the start of a
long-term-support (LTS) phase. This release hits the goal of 1.0.0 of a stable API, outstanding issues closed,
a correctness fix at the core of predictInterval(), and modularity in the core prediction interval functionality.
The documentation is also now available [via a pkgdown site as well!](https://jknowles.github.io/merTools)
merTools has been on CRAN since 2015, with over 457,000 downloads and about
8,000 a month. It exists to get the most out of large mixed-effects models fit
with lme4
. Its headline function,
predictInterval(), produces prediction intervals for lmer/glmer models
by simulating from the joint distribution of the fixed and random effects — the
approach from Gelman and Hill (2007),1 the same machinery behind arm::sim().
The motivation is practical. lme4::bootMer() and full MCMC give you principled
uncertainty, but on models with tens of thousands of groups they can be
impractical or simply too slow to use interactively.
predictInterval() is built to give you honest intervals on exactly those
models, in about a second.
The obvious question for a simulation-based approximation is how close it is to
doing the full Bayesian thing. When we first wrote merTools brms was in its infancy, but
since then it has become my go-to for most Bayesian inference and, frankly, made much of merTools obsolete.
I used an LLM to assist me with refactoring the code and responding to open issues, so I wanted to create a new
set of tests and benchmarks to validate that the package still worked.
So for 1.0 I created a new short vignette that compares brms and merTools results side by side:
the same data and the same model — the bundled hsb data (7,185 students in 160 schools),
modeling math achievement from student SES, school-mean SES, and a school-varying
SES slope. We hold out 20% of students to test on.
data(hsb)hsb$schid<-factor(hsb$schid)new_schools<-sample(levels(hsb$schid),6)hsb$.set<-"train"hsb$.set[hsb$schid%in%new_schools]<-"test_new"seen<-which(hsb$.set=="train")hsb$.set[sample(seen,round(0.2*length(seen)))]<-"test_seen"train<-droplevels(hsb[hsb$.set=="train",])test_seen<-hsb[hsb$.set=="test_seen"&hsb$schid%in%levels(train$schid),]f1<-mathach~ses+meanses+(ses|schid)m_lme<-lmer(f1,data=train)# Fit brms once and cache it. Persist the genuine from-scratch fit time to a# file, so the timing table below reports the real compile+sample cost even on# later renders that just read the cached fit (which take ~2s, not ~7 min).brms_cache<-file.path(outdir,"brms_hsb_meanses.rds")time_cache<-file.path(outdir,"brms_hsb_meanses_seconds.rds")fresh_fit<-!file.exists(brms_cache)elapsed<-system.time(m_brm<-fit_brm(f1,train,gaussian(),"brms_hsb_meanses"))[["elapsed"]]if(fresh_fit)saveRDS(elapsed,time_cache)brms_fit_seconds<-if(file.exists(time_cache))readRDS(time_cache)elseelapsed
The real test is out-of-sample: do nominal intervals cover held-out scores at the
nominal rate? We draw a full predictive distribution for each held-out student
from each method — predictInterval(returnSims = TRUE) and
brms::posterior_predict() — and compare empirical coverage. Both track the
nominal level, and each other.
The mt_draws() helper used below — saved alongside the analysis — just wraps
predictInterval() to hand back the raw simulation matrix:
helpers.R
# One column of posterior-style draws per row of `newdata`.mt_draws<-function(fit,newdata,...){pi<-predictInterval(fit,newdata=newdata,returnSims=TRUE,...)attr(pi,"sim.results")}
t_lme<-system.time(lmer(f1,data=train))[["elapsed"]]t_mt<-system.time(mt_draws(m_lme,test_seen))[["elapsed"]]t_pp<-system.time(posterior_predict(m_brm,newdata=test_seen,allow_new_levels=TRUE))[["elapsed"]]data.frame(step=c("lme4 fit","predictInterval","brms fit (compile+sample)","posterior_predict"),seconds=round(c(t_lme,t_mt,brms_fit_seconds,t_pp),2))
The entire lme4 + predictInterval() path runs in about a second; the single
brms fit takes several minutes — a couple of orders of magnitude, and the gap
only widens on the large models predictInterval() was really built for. The
point isn’t to stop using brms: if you want the full posterior, use it. The point
is that when full MCMC is impractical, predictInterval() is a fast,
well-calibrated stand-in. The full story — new-group handling and a binomial GLMM
— is in the
validation vignette
.
When full MCMC is impractical, predictInterval() is a fast, well-calibrated stand-in.
New in 1.0, plotREimpact() visualizes REimpact() output — the fitted outcome
across the distribution of a grouping factor’s effect. Pass a named list and it
overlays grouping factors on shared axes, so you can compare their influence
directly. Here, the instructor and student effects in the InstEval ratings data:
Figure. Instructor effect moves the predicted rating more than the student effect.
Moving a case from the bottom to the top of the instructor-effect distribution
shifts the predicted rating substantially more than the same move across the
student distribution — the instructor grouping factor carries more of the signal.
The release notes
have
the full list; the highlights:
Correctness fix for nested random effects (#124).predictInterval() was
returning seed-dependent point estimates when a prediction frame mixed observed
and unobserved levels of an interaction grouping factor (e.g. (1 | a/b)). A
max.col() tie-break was silently letting an unobserved level borrow a
random observed level’s effect. Unobserved levels now correctly fall back to
the fixed effects; observed-level predictions are bit-for-bit unchanged.
New new.levels = "draw". For a group the model never saw, the default
("zero") drops its random effect; "draw" instead samples the effect from
the estimated random-effect covariance — the direct analogue of
brms::posterior_predict(allow_new_levels = TRUE). The default is unchanged.
plotFEsim() now highlights significant terms, and shinyMer() is
revived and extended with a Model Summary tab and subset-based draws.
merTools does what it set out to do, and the API has been stable for years. Going
forward, 1.0.x releases will be about keeping it healthy — bug fixes, CRAN and
dependency compatibility, and documentation — rather than churning the interface.
Thanks to everyone who has contributed over the years — Carl Frederick, Alex
Whitworth, Ben Bolker (@bbolker), Davis Vaughan (@DavisVaughan) — and to the
issue reporters who made this release better, including @dotPiano, whose report
led to the #124 correctness fix.
Gelman,
A. & Hill,
J.
(2007).
Data analysis using regression and multilevel/hierarchical models.
Cambridge University Press.
Gelman & Hill, Data Analysis Using Regression and Multilevel/Hierarchical
Models (Cambridge University Press, 2007), ch. 12 — the simulation approach
predictInterval() implements. ↩︎
]]>
{
"attach_link": true,
"format_string": "{{title}}\n\n{{summary}}",
"og_description": "After a decade on CRAN, merTools reaches 1.0 — feature complete, in long-term support, and now benchmarked head-to-head against full Bayesian inference.",
"og_image": "https://jaredknowles.com/og/posts/mertools-1-0-released.png",
"og_title": "merTools 1.0: prediction intervals for mixed models, validated against brms"
}
Education Data Done Right, a New Book on Strategies for Success in Building Education Data Capacityhttps://jaredknowles.com/posts/education-data-done-right-a-new-book-on-strategies-for-success-in-building-education-data-capacity/2019-10-23T21:31:30Z2019-10-23T21:31:30ZNew book covers the ins and outs of doing education data analysis well in public education agencies from the perspective of three analysts with decades of experience in the field. Boston, MA – October 7, 2019 – Wendy Geller, Dorothyjean Cratty, and Jared Knowles – three data analysts with expertise in public education agencies – have teamed up to write a new book which covers the missing elements that are critical to success in building data capacity in education agencies. The book is intended for education agency data analysts, teams of analyst, and data managers, strategists, and leaders seeking to improve how their agency operates.
New book covers the ins and outs of doing education data analysis well in public education agencies from the perspective of three analysts with decades of experience in the field.
Boston, MA – October 7, 2019 – Wendy Geller, Dorothyjean Cratty, and Jared Knowles – three data analysts with expertise in public education agencies – have teamed up to write a new book which covers the missing elements that are critical to success in building data capacity in education agencies. The book is intended for education agency data analysts, teams of analyst, and data managers, strategists, and leaders seeking to improve how their agency operates.
Many education agency data analysts come from a social science research background and the transition to work inside agencies can come with a lot of new challenges. This book is a guide through those challenges covering topics such as metadata, data requests, how to work with IT, politics, and descriptive data analysis.
The book covers these topics with wit and humor and a perspective only possible from authors who’ve been in the trenches and gotten the work done. Each chapter was reviewed by another expert in the field who gave valuable outside perspective and broadened the horizon of the book to ensure its relevance for agencies across the country.
The book is accompanied by a website where analysts across the country can get in touch and suggest contributions for planned future volumes. On the website
you can also learn more about the biographies of the authors and each of the contributors.
Education Data Done Right (EDDR) is available now digitally on LeanPub with a suggested price of $15: www.leanpub.com/eddatadoneright
Print copies available at Amazon
.
About the Authors
Dr. Wendy Geller is currently the Director of the Data Management & Analysis Division. There, she leads a team that serves as a centralized resource to the Vermont Agency of Education. Her crew collects, stewards, and leverages the institution’s critical data assets to create and share data products that enable empirically-based practice and policy decision-making.
Dr. Jared Knowles is formerly a research analyst at the Wisconsin Department of Public Instruction (2011-2016) and is currently the president of Civilytics Consulting LLC, which provides training, analytic services, and strategy to education agencies across the country.
Ms. Dorothyjean Cratty is formerly a research associate at the U.S. Department of Education. She is currently the founder of DJC Applied Research, which provides high-quality in-depth data analysis of administrative education data.
Data Requests: You Can Make them Useful (we swear)
Politics and Data Driven Decision Making
Moments of Truth: Why Calculating Descriptive Statistics is Important
Applying Tools of the Trade: Descriptive Data Commands in Context
Conclusions
]]>
{
"attach_link": true,
"format_string": "{{title}}\n\n{{summary}}",
"og_description": "New book covers the ins and outs of doing education data analysis well in public education agencies from the perspective of three analysts with decades of experience in the field. Boston, MA – October 7, 2019 – Wendy Geller, Dorothyjean Cratty, and Jared Knowles – three data analysts with expertise in public education agencies – have teamed up to write a new book which covers the missing elements that are critical to success in building data capacity in education agencies. The book is intended for education agency data analysts, teams of analyst, and data managers, strategists, and leaders seeking to improve how their agency operates.",
"og_image": "https://jaredknowles.com/og/posts/education-data-done-right-a-new-book-on-strategies-for-success-in-building-education-data-capacity.png",
"og_title": "Education Data Done Right, a New Book on Strategies for Success in Building Education Data Capacity"
}
The Ethics of Data Sciencehttps://jaredknowles.com/posts/the-ethics-of-data-science/2019-07-12T14:29:56Z2019-07-12T14:29:56ZThe past 18 months I’ve spent a lot of time thinking about the role of experts in a democratic society. Experts pose a particular challenge to democratic governance because expertise is, by its nature, undemocratic. A lot of this thinking has been centered around a particular kind of expertise - perhaps the defining type of expertise of our time - data science. I have been happy to find that a number of very talented researchers and authors have been taking up the question of data science and its role in our society lately. In the past several years a number of thought-provoking and brilliant books and articles have been written that demand the attention of anyone working in data science - but particularly those working in fields where the impact of their work is public.The past 18 months I’ve spent a lot of time thinking about the role of experts in a democratic society. Experts pose a particular challenge to democratic governance because expertise is, by its nature, undemocratic. A lot of this thinking has been centered around a particular kind of expertise - perhaps the defining type of expertise of our time - data science.
I have been happy to find that a number of very talented researchers and authors have been taking up the question of data science and its role in our society lately. In the past several years a number of thought-provoking and brilliant books and articles have been written that demand the attention of anyone working in data science - but particularly those working in fields where the impact of their work is public.
Instead of adding my interpretation of these works I thought it would be more helpful to direct you to engage with these authors directly. To aid in that I have put together a reading list of the books and articles that have been the most eye-opening and thought provoking for me in the hopes they may provide the same for you.
Below is an annotated version of this list which captures my recommendations for which books and articles might be most useful to different types of readers. You can get it as a PDF here.
This reading list gives an overview of the ethical concerns specific to data analysis, data science, and artificial intelligence. Ethics is used broadly here to mean concerns related to racial and economic equity, justice, fairness, and the protection of democratic and human rights.
This list is intended to spark new ideas and prompt critical thinking about data system design and integration into business processes in an organization. This is not an endorsement of all viewpoints represented in the readings below – except to say that each of the readings raise questions, put forward ideas, and make critiques that are worthy of your deep consideration.
All links last accessed July 11th, 2019. This guide was last updated July 11th, 2019. An unannotated version of this reading list is available on GitHub
. You can get an updated version of this list as well as suggest additions to the reading list there.
Eubanks, Virginia. 2018. Automating Inequality. St. Martin’s Press.
Noble, Safiya. 2018. Algorithms of Oppression: How Search Engines Reinforce Racism. NYU Press.
O’Neil, Cathy. 2016. Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy. Broadway Books.
These are the “big three” books uncovering the ways that algorithms affect our lives invisibly and sometimes visibly. Of the three I am partial to Eubanks because of the in-depth way she centers the voices of those affected by algorithms and her focus on algorithms in the social services sector. Noble is one of the most important voices in technology today – especially for thinking about the impact of major technology companies on our lives. I prefer the article below to the book length treatment by O’Neil. The intersection of expertise and democracy has been studied by social scientists for decades and that literature is better summarized elsewhere.
Broussard, Meredith. 2018. Artificial Unintelligence: How Computers Misunderstand the World. MIT Press.
Benjamin, Ruha. 2019. Race After Technology: Abolitionist Tools for the New Jim Code. Polity.
These are two newer texts which offer updated takes on the above themes. Broussard is specifically tackling artificial intelligence which is related to, but adjacent to most applications of data science in fields like education and social services (for now). Benjamin’s book is one I anticipate greatly as it brings a much needed critical race perspective to the conversation about the affect of data analysis and collection on our society. Even better it is intended to teach the reader how to critically review the promises of technologies like algorithms and automated decision support systems.
Loukides, Mike, Hilary Mason, and DJ Patil. 2018. Ethics and Data Science. O’Reilly.
This is a pragmatic and brief overview of the major ethical concerns with data science. This text focuses on practical steps that a data science team can take to be more ethical. This practical approach is different than the above readings which is why I recommend it as a supplementary reading – but is very helpful for answering the “what do I do now?” question.
This book isn’t about ethics, data science, or technology explicitly at all. It is about how to work together with a large inclusive set of stakeholders to build something that reflects the voices of a diverse community. This is, in fact, the main solution proposed by almost all the authors above – inclusive design done together with a wider community. This book will stimulate your thinking on how to go about that.
Wallach, Hanna. 2014. “Big Data, Machine Learning, and the Social Sciences: Fairness, Accountability, and Transparency.” Medium. Online
. 12.19.2014
O’Neil, Cathy. 2016. “How to Bring Better Ethics to Data Science.” Slate. Online
. 2.4.2016
Broussard, Meredith. 2019. “Letting Go of Technochauvinism.” in Public Books. Online
. 6.17.2019.
Together these three articles provide a great overview of the limits of data science, the limits of our ability to “technology” our way out of social problems, and the intersection of the data systems we design and the world we live in. The Broussard article challenges the reader with the proposition that automation is perhaps not the best answer to each and every problem. The O’Neil article is a great overview of her critically acclaimed book – clearly presenting the arguments and the implications. The Wallach piece is maybe the best of the bunch – it gives a comprehensive tour of the ethical concerns of data science starting from the questions we ask all the way through how we use the answers our algorithms provide.
Dash is one of the most important voices in the tech industry. While not strictly about data science, this series of articles provides a great overview for thinking about how to build technology tools for society as it is in ways that make society better – instead of exploiting the flaws in our society for profit. You should also check out his podcast – Function
.
Fischer, Frank. 1993. “Citizen participation and democratization of policy expertise: From theoretical inquiry to practical cases*.*” Policy Sciences. v. 26 pp. 165-187.
Diakopoulos, Nicholas. 2016. “How to Hold Governments Accountable for the Algorithms They Use.” Slate. Online
. 2.11.2016
Government uses of data science tools are a special case and merit their own discussion. Dakopoulos and Angwin both present good overviews for how to make algorithms in government accountable and how to enforce accountability of algorithms in general. For me, though, the take on this topic that expanded my mind the most was an older article on the role of expertise in governing a democratic society by Fischer. This article is heavy on the academic side but takes a look at the unique challenges that a reliance on expertise poses to a democratically governed society.
Patil, DJ. 2016. “A Code of Ethics for Data Science.” Medium. Online
. 2.1.2018
Wheeler, Schaun. 2018. “An ethical code can’t be about ethics.” Towards Data Science. Online
. 2.6.2018
Eubanks, Virginia. 2018. “A Hippocratic Oath for Data Science*.*” Online
. 2.21.2018
There has been a healthy debate about a “Hippocratic Oath” for Data Science or a “Data Science Code of Ethics”. These articles provide different viewpoints on that debate and help think about what it means to ethically do data science and what role a professional code of ethics may play.
Venkatasubramanian, Suresh and Katie Shelef. 2017. “Ethics of Data Science Course Syllabus.” University of Utah. Online
.
This syllabus contains a lot of foundational texts in the ethics of social science as well as a wonderful set of examples of the ethical challenges posed by data science.
Malliaraki, Eirini. 2018. “Toward ethical, transparent and fair AI/ML: a critical reading list.” Medium. Online
.
This is the closest thing to a comprehensive current reading list on transparency and fairness in machine learning and artificial intelligence. This thorough and well-organized reading list has plenty of great further reading to extend on any of the readings covered here.
Wickham, Hadley. 2018. “Readings in Applied Data Science.” Online
.
A wide-ranging reading list of applied data science topics. Some would make great case studies for ethical dilemmas in data science, others are critical analyses of the ethics of particular applications of data science.
Various. 2018. Readings in Data Ethics. O’Reilly. Online
.
Five short articles that will give you a practical and pragmatic overview for how to implement some ethical safeguards into your data science team and products.
]]>
{
"attach_link": true,
"format_string": "{{title}}\n\n{{summary}}",
"og_description": "The past 18 months I’ve spent a lot of time thinking about the role of experts in a democratic society. Experts pose a particular challenge to democratic governance because expertise is, by its nature, undemocratic. A lot of this thinking has been centered around a particular kind of expertise - perhaps the defining type of expertise of our time - data science. I have been happy to find that a number of very talented researchers and authors have been taking up the question of data science and its role in our society lately. In the past several years a number of thought-provoking and brilliant books and articles have been written that demand the attention of anyone working in data science - but particularly those working in fields where the impact of their work is public.",
"og_image": "https://jaredknowles.com/og/posts/the-ethics-of-data-science.png",
"og_title": "The Ethics of Data Science"
}
Learn More About Civilyticshttps://jaredknowles.com/posts/learn-more-about-civilytics/2019-03-20T14:15:13Z2019-03-20T14:15:13ZCivilytics Consulting is an LLC founded by me in 2016 to pursue my goals of providing capacity-building data science services to public institution partners. Now that we are in our third year there will be lots of new developments to announce in 2019 - so stay tuned. For now, I thought I would share this snapshot of where Civilytics is and what we do: About Civilytics # Civilytics Consulting is a data science consulting firm founded in 2016 by me, Dr. Jared E. Knowles. Civilytics has served clients at all levels of government in several policy areas including K-12 education, higher education, policing, and taxation. Dr. Knowles pioneered an award-winning machine learning algorithm for the state of Wisconsin that is used across the state to help struggling students get back on track. Since 2012, his work has been used around the country to improve the accuracy of predictive analytics systems in education. He has been published in several peer-reviewed journals, including the Journal of Educational Data Mining and Journal of Policy Analysis and Management. He has a Ph.D. in Political Science with expertise in the management and governance of publicly-run education agencies. He has advised government agencies in a variety of sectors on the development, business use, and policy implications of machine learning tools to augment human decision making.Civilytics Consulting is an LLC founded by me in 2016 to pursue my goals of providing capacity-building data science services to public institution partners. Now that we are in our third year there will be lots of new developments to announce in 2019 - so stay tuned. For now, I thought I would share this snapshot of where Civilytics is and what we do:
Civilytics Consulting is a data science consulting firm founded in 2016 by me, Dr. Jared E. Knowles. Civilytics has served clients at all levels of government in several policy areas including K-12 education, higher education, policing, and taxation. Dr. Knowles pioneered an award-winning machine learning algorithm for the state of Wisconsin that is used across the state to help struggling students get back on track. Since 2012, his work has been used around the country to improve the accuracy of predictive analytics systems in education. He has been published in several peer-reviewed journals, including the Journal of Educational Data Mining and Journal of Policy Analysis and Management. He has a Ph.D. in Political Science with expertise in the management and governance of publicly-run education agencies. He has advised government agencies in a variety of sectors on the development, business use, and policy implications of machine learning tools to augment human decision making.
Civilytics Consulting focuses on building the capacity of its public institution partners to sustain analytic products after the initial work. By using open source software and open data sources, providing all source code and extensive documentation, and excellent training of customers in the product, Civilytics ensures that its clients can maintain products developed long after the contract ends. This sustainable partnership model is unique, allowing agencies to build lasting organizational change. Civilytics approaches projects with a human centered design methodology that creates lasting partnerships with clients.
building an enrollment projection system for a state higher education system
building an equity focused dashboard and reporting tool for student recruitment
designing a curriculum for data analysts in education agencies
developing an open platform for education analysts to reproduce results using synthetic data to protect confidential records and increase collaboration
Past Projects
advised on the development of a statewide college and career readiness identification system and high school graduation early warning system
audited and reviewed predictive models for a number of local government services
built programmatic city accountability reports on police performance
a published review of public data sources available to integrate with State Longitudinal Data Systems (SLDSs)
]]>
{
"attach_link": true,
"format_string": "{{title}}\n\n{{summary}}",
"og_description": "Civilytics Consulting is an LLC founded by me in 2016 to pursue my goals of providing capacity-building data science services to public institution partners. Now that we are in our third year there will be lots of new developments to announce in 2019 - so stay tuned. For now, I thought I would share this snapshot of where Civilytics is and what we do: About Civilytics # Civilytics Consulting is a data science consulting firm founded in 2016 by me, Dr. Jared E. Knowles. Civilytics has served clients at all levels of government in several policy areas including K-12 education, higher education, policing, and taxation. Dr. Knowles pioneered an award-winning machine learning algorithm for the state of Wisconsin that is used across the state to help struggling students get back on track. Since 2012, his work has been used around the country to improve the accuracy of predictive analytics systems in education. He has been published in several peer-reviewed journals, including the Journal of Educational Data Mining and Journal of Policy Analysis and Management. He has a Ph.D. in Political Science with expertise in the management and governance of publicly-run education agencies. He has advised government agencies in a variety of sectors on the development, business use, and policy implications of machine learning tools to augment human decision making.",
"og_image": "https://jaredknowles.com/og/posts/learn-more-about-civilytics.png",
"og_title": "Learn More About Civilytics"
}
Announcing a major update to merToolshttps://jaredknowles.com/posts/announcing-a-major-update-to-mertools/2016-12-13T13:36:16Z2016-12-13T13:36:16ZmerTools is an R package that is designed to make working with multilevel models from lme4, particularly large models with many random effects, fast and easy. With merTools you can generate prediction intervals that incorporate various components of uncertainty (fixed effect, random effect, and model uncertainty), you can get the expected rank of individual random effect levels (a combination of magnitude and precision of the estimate) and you can explore the substantive effect of variables in the model using a Shiny application interactively!merTools is an R package that is designed to make working with multilevel models from lme4, particularly large models with many random effects, fast and easy. With merTools you can generate prediction intervals that incorporate various components of uncertainty (fixed effect, random effect, and model uncertainty), you can get the expected rank of individual random effect levels (a combination of magnitude and precision of the estimate) and you can explore the substantive effect of variables in the model using a Shiny application interactively!
Recently, we’ve updated the package to significantly improve performance and accuracy. You can get it on CRAN now.
Below are some updates from the NEWS.md. To learn more check out the package development on GitHub
. You can also read previous a previous blog entry discussing
the package and its uses.
Improve handling of formulas. If the original merMod has functions specified
in the formula, the draw and wiggle functions will check for this and attempt
to respect these variable transformations. Where this is not possible a warning
will be issued. Most common transformations are respected as long as the the
original variable is passed untransformed to the model.
Change the calculations of the residual variance. Previously residual variance
was used to inflate both the variance around the fixed parameters and around the
predicted values themselves. This was incorrect and resulted in overly conservative
estimates. Now the residual variance is appropriately only used around the
final predictions
New option for predictInterval that allows the user to return the full
interval, the fixed component, the random component, or the fixed and each random
component separately for each observation
Fixed a bug with slope+intercept random terms that caused a miscalculation of
the random component
Add comparison to rstanarm to the Vignette
Make expectedRank output more tidy like and allow function to calculate
expected rank for all terms at once
Note, this breaks the API by changing the names of the columns in the output
of this function
Remove tests that test for timing to avoid issues with R-devel JIT compiler
Remove plyr and replace with dplyr
Fix issue #62 varList will now throw an error if == is used instead of =
Fix issue #54 predictInterval did not included random effects in calculations
when newdata had more than 1000 rows and/or user specified parallel=TRUE.
Note: fix was to disable the .paropts option for predictInterval … user
can still specify for temporary backward compatibility but this should be
either removed or fixed in the permanent solution.
Fix issue #53 about problems with predictInterval when only specific levels
of a grouping factor are in newdata with the colon specification of
interactions
Fix issue #52 ICC wrong calculations … we just needed to square the standard
deviations that we pulled
]]>
{
"attach_link": true,
"format_string": "{{title}}\n\n{{summary}}",
"og_description": "merTools is an R package that is designed to make working with multilevel models from lme4, particularly large models with many random effects, fast and easy. With merTools you can generate prediction intervals that incorporate various components of uncertainty (fixed effect, random effect, and model uncertainty), you can get the expected rank of individual random effect levels (a combination of magnitude and precision of the estimate) and you can explore the substantive effect of variables in the model using a Shiny application interactively!",
"og_image": "https://jaredknowles.com/og/posts/announcing-a-major-update-to-mertools.png",
"og_title": "Announcing a major update to merTools"
}
Introducing the R Data Science Livestreamhttps://jaredknowles.com/posts/introducing-the-r-data-science-livestream/2016-09-22T15:37:03Z2016-09-22T15:37:03ZHave you ever watched a livestream? Have you ever wondered what the actual minute to minute of doing data science looks like? Do you wonder if other R users have the same frustrations as you? If yes – then read on! I’m off on a new professional adventure where I am doing public facing work for the first time in years. While working at home the other day I thought it would be a great idea to keep myself on-task and document my decisions if I recorded myself working with my webcam. Then, I thought, why stop there – why not livestream my work?Have you ever watched a livestream? Have you ever wondered what the actual minute to minute of doing data science looks like? Do you wonder if other R users have the same frustrations as you? If yes – then read on!
I’m off on a new professional adventure where I am doing public facing work for the first time in years. While working at home the other day I thought it would be a great idea to keep myself on-task and document my decisions if I recorded myself working with my webcam. Then, I thought, why stop there – why not livestream my work?
And thus, the R Data Science Livestream
was born. The idea is that every day for an hour or two I will livestream myself doing some data science tasks related to my current project – which is to analyze dozens of years of FBI Uniform Crime reports (read more
). I haven’t done much R coding in the last 4 months, so it’s also a good way to shake off the rust of being out of the game for so long.
]]>
{
"attach_link": true,
"format_string": "{{title}}\n\n{{summary}}",
"og_description": "Have you ever watched a livestream? Have you ever wondered what the actual minute to minute of doing data science looks like? Do you wonder if other R users have the same frustrations as you? If yes – then read on! I’m off on a new professional adventure where I am doing public facing work for the first time in years. While working at home the other day I thought it would be a great idea to keep myself on-task and document my decisions if I recorded myself working with my webcam. Then, I thought, why stop there – why not livestream my work?",
"og_image": "https://jaredknowles.com/og/posts/introducing-the-r-data-science-livestream.png",
"og_title": "Introducing the R Data Science Livestream"
}
Explore multilevel models faster with the new merTools R packagehttps://jaredknowles.com/posts/announcing-mertools/2015-09-23T13:49:00Z2015-09-23T13:49:00ZUpdate 1: Package is now available on CRAN . Update 2: Development version also supports models from the blme package. By far the most popular content on this blog are my two tutorials on how to fit and use multilevel models in R. Since publishing those tutorials I have received numerous questions, comments, and hits to this blog looking for more information about multilevel models in R. Since my day job involves fitting and exploring multilevel models, as well as explaining them to a non-technical audience, I began working with my colleague Carl Frederick on an R package to make these tasks easier. Today, I’m happy to announce that our solution, merTools , is now available. Below, I reproduce the package README file, but you can find out more on GitHub. There are two extensive vignettes that describe how to make use of the package, as well as a shiny app that allows interactive model exploration. The package should be available on CRAN within the next few days.Update 1: Package is now available on CRAN
.
Update 2: Development version also supports models from the blme package.
By far the most popular content on this blog are my two tutorials on how to fit and use multilevel models in R. Since publishing those tutorials I have received numerous questions, comments, and hits to this blog looking for more information about multilevel models in R. Since my day job involves fitting and exploring multilevel models, as well as explaining them to a non-technical audience, I began working with my colleague Carl Frederick on an R package to make these tasks easier. Today, I’m happy to announce that our solution, merTools
, is now available. Below, I reproduce the package README file, but you can find out more on GitHub. There are two extensive vignettes that describe how to make use of the package, as well as a shiny app that allows interactive model exploration. The package should be available on CRAN within the next few days.
Working with generalized linear mixed models (GLMM) and linear mixed models (LMM) has become increasingly easy with advances in the lme4 package. As we have found ourselves using these models more and more within our work, we, the authors, have developed a set of tools for simplifying and speeding up common tasks for interacting with merMod objects from lme4. This package provides those tools.
The easiest way to demo the features of this application is to use the bundled Shiny application which launches a number of the metrics here to aide in exploring the model. To do this:
devtools::install_github("jknowles/merTools")library(merTools)m1<-lmer(y~service+lectage+studage+(1|d)+(1|s),data=InstEval)shinyMer(m1,simData=InstEval[1:100,])# just try the first 100 rows of data
On the first tab, the function presents the prediction intervals for the data selected by user which are calculated using the predictInterval function within the package. This function calculates prediction intervals quickly by sampling from the simulated distribution of the fixed effect and random effect terms and combining these simulated estimates to produce a distribution of predictions for each observation. This allows prediction intervals to be generated from very large models where the use of bootMer would not be feasible computationally.
On the next tab the distribution of the fixed effect and group-level effects is depicted on confidence interval plots. These are useful for diagnostics and provide a way to inspect the relative magnitudes of various parameters. This tab makes use of four related functions in merTools: FEsim, plotFEsim, REsim and plotREsim which are available to be used on their own as well.
On the third tab are some convenient ways to show the influence or magnitude of effects by leveraging the power of predictInterval. For each case, up to 12, in the selected data type, the user can view the impact of changing either one of the fixed effect or one of the grouping level terms. Using the REimpact function, each case is simulated with the model’s prediction if all else was held equal, but the observation was moved through the distribution of the fixed effect or the random effect term. This is plotted on the scale of the dependent variable, which allows the user to compare the magnitude of effects across variables, and also between models on the same data.
Note that predictInterval is slower because it is computing simulations. It can also return all of the simulated yhat values as an attribute to the predict object itself.
predictInterval uses the sim function from the arm package heavily to draw the distributions of the parameters of the model. It then combines these simulated values to create a distribution of the yhat for each observation.
merTools also provides functionality for inspecting merMod objects visually. The easiest are getting the posterior distributions of both fixed and random effect parameters.
Note that plotREsim highlights group levels that have a simulated distribution that does not overlap 0 – these appear darker. The lighter bars represent grouping levels that are not distinguishable from 0 in the data.
Sometimes the random effects can be hard to interpret and not all of them are meaningfully different from zero. To help with this merTools provides the expectedRank function, which provides the percentile ranks for the observed groups in the random effect distribution taking into account both the magnitude and uncertainty of the estimated effect for each group.
It can still be difficult to interpret the results of LMM and GLMM models, especially the relative influence of varying parameters on the predicted outcome. This is where the REimpact and the wiggle functions in merTools can be handy.
The result of REimpact shows the change in the yhat as the case we supplied to newdata is moved from the first to the fifth quintile in terms of the magnitude of the group factor coefficient. We can see here that the individual professor effect has a strong impact on the outcome variable. This can be shown graphically as well:
library(ggplot2)ggplot(impSim,aes(x=factor(bin),y=AvgFit,ymin=AvgFit-1.96*AvgFitSE,ymax=AvgFit+1.96*AvgFitSE))+geom_pointrange()+theme_bw()+labs(x="Bin of `d` term",y="Predicted Fit")
Here the standard error is a bit different – it is the weighted standard error of the mean effect within the bin. It does not take into account the variability within the effects of each observation in the bin – accounting for this variation will be a future addition to merTools.
]]>
{
"attach_link": true,
"format_string": "{{title}}\n\n{{summary}}",
"og_description": "Update 1: Package is now available on CRAN . Update 2: Development version also supports models from the blme package. By far the most popular content on this blog are my two tutorials on how to fit and use multilevel models in R. Since publishing those tutorials I have received numerous questions, comments, and hits to this blog looking for more information about multilevel models in R. Since my day job involves fitting and exploring multilevel models, as well as explaining them to a non-technical audience, I began working with my colleague Carl Frederick on an R package to make these tasks easier. Today, I’m happy to announce that our solution, merTools , is now available. Below, I reproduce the package README file, but you can find out more on GitHub. There are two extensive vignettes that describe how to make use of the package, as well as a shiny app that allows interactive model exploration. The package should be available on CRAN within the next few days.",
"og_image": "https://jaredknowles.com/og/posts/announcing-mertools.png",
"og_title": "Explore multilevel models faster with the new merTools R package"
}
Version 0.9.0 of eeptools released!https://jaredknowles.com/posts/version-090-of-eeptools-released/2015-09-22T17:09:54Z2015-09-22T17:09:54ZA long overdue overhaul of my eeptools package for R was released to CRAN today and should be showing up in the mirrors soon. The release notes for this version are extensive as this represents a modernization of the package infrastructure and the reimagining of many of the utility functions contained in the package. From the release notes: This is a major update including removing little used functions and renaming and restructuring functions.A long overdue overhaul of my eeptools package for R was released to CRAN today and should be showing up in the mirrors soon. The release notes for this version are extensive as this represents a modernization of the package infrastructure and the reimagining of many of the utility functions contained in the package. From the release notes:
This is a major update including removing little used functions and renaming
and restructuring functions.
nsims in gelmansim was renamed to n.sims to align with the arm package
Fixed bug in retained_calc where user specified sid resulted in wrong
ids being returned
Inserted a meaningful error in age_calc when the enddate is before the date
of birth
Fixed issue with age_calc which lead to wrong fraction of age during leap
years
lag_data now can do leads and lags and includes proper error messages
fix major bugs for statamode including faulty default to method and returning
objects of the wrong class
add unit tests and continuous integration support for better package updating
fix behavior of max_mis in cases when it is passed an empty vector or a
vector of NA
leading_zero function made robust to negative values
added NA handling options to cutoff and thresh
Codebase is now tested with lintr to improve readability
]]>
{
"attach_link": true,
"format_string": "{{title}}\n\n{{summary}}",
"og_description": "A long overdue overhaul of my eeptools package for R was released to CRAN today and should be showing up in the mirrors soon. The release notes for this version are extensive as this represents a modernization of the package infrastructure and the reimagining of many of the utility functions contained in the package. From the release notes: This is a major update including removing little used functions and renaming and restructuring functions.",
"og_image": "https://jaredknowles.com/og/posts/version-090-of-eeptools-released.png",
"og_title": "Version 0.9.0 of eeptools released!"
}
Announcing the caretEnsemble R packagehttps://jaredknowles.com/posts/announcing-the-caretensemble-package-for-r/2015-01-20T15:31:04Z2015-01-20T15:31:04ZLast week version 1.0 of the caretEnsemble package was released to CRAN. I have co-authored this package with Zach Mayer , who had the original idea of allowing for ensembles of train objects in the caret package. The package is designed to make it easy for the user to optimally combine models of various types together to produce a meta-model with superior fit than the sub-models. From the vignette: "caretEnsemble has 3 primary functions: caretList, caretEnsemble and caretStack. caretList is used to build lists of caret models on the same training data, with the same re-sampling parameters. caretEnsemble andcaretStack are used to create ensemble models from such lists of caret models. caretEnsemble uses greedy optimization to create a simple linear blend of models and caretStack uses a caret model to combine the outputs from several component caret models." I am excited about this package because the ensembling features in caretEnsemble are used to provide additional predictive power in the Wisconsin Dropout Early Warning System (DEWS). I’ve written about this system before , but it is a large-scale machine learning system used to provide schools with a prediction on the likely graduation of their middle grade students. It is easy to implement and provides additional predictive power for the cost of some CPU cycles.Last week version 1.0 of the caretEnsemble
package was released to CRAN. I have co-authored this package with Zach Mayer
, who had the original idea of allowing for ensembles of train objects in the caret
package. The package is designed to make it easy for the user to optimally combine models of various types together to produce a meta-model with superior fit than the sub-models.
"caretEnsemble has 3 primary functions: caretList, caretEnsemble and caretStack. caretList is used to build lists of caret models on the same training data, with the same re-sampling parameters. caretEnsemble andcaretStack are used to create ensemble models from such lists of caret models. caretEnsemble uses greedy optimization to create a simple linear blend of models and caretStack uses a caret model to combine the outputs from several component caret models."
Additionally, Zach and I have worked hard to make ensembling models *easy*. For example, you can automatically build lists of models – a library of models – for ensembling using the caretList function. This caretList can then be used directly in either the caretEnsemble or caretStack mode, depending on how you want to combine the predictions from the submodels. These new caret objects also come with their own S3 methods (adding more in future releases) to allow you to interact with them and explore the results of ensembling – including summary, print, plot, and variable importance calculations. They also include the all important predict method allowing you to generate predictions for use elsewhere.
Zach has written a great vignette
that should give you a feel for how caretEnsemble works. And, we are actively improving caretEnsemble over on GitHub
. Drop by and let us know if you find a bug, have a feature request, or want to let us know how it is working for you!
]]>
{
"attach_link": true,
"format_string": "{{title}}\n\n{{summary}}",
"og_description": "Last week version 1.0 of the caretEnsemble package was released to CRAN. I have co-authored this package with Zach Mayer , who had the original idea of allowing for ensembles of train objects in the caret package. The package is designed to make it easy for the user to optimally combine models of various types together to produce a meta-model with superior fit than the sub-models. From the vignette: \"caretEnsemble has 3 primary functions: caretList, caretEnsemble and caretStack. caretList is used to build lists of caret models on the same training data, with the same re-sampling parameters. caretEnsemble andcaretStack are used to create ensemble models from such lists of caret models. caretEnsemble uses greedy optimization to create a simple linear blend of models and caretStack uses a caret model to combine the outputs from several component caret models.\" I am excited about this package because the ensembling features in caretEnsemble are used to provide additional predictive power in the Wisconsin Dropout Early Warning System (DEWS). I’ve written about this system before , but it is a large-scale machine learning system used to provide schools with a prediction on the likely graduation of their middle grade students. It is easy to implement and provides additional predictive power for the cost of some CPU cycles.",
"og_image": "https://jaredknowles.com/og/posts/announcing-the-caretensemble-package-for-r.png",
"og_title": "Announcing the caretEnsemble R package"
}
On Early Warning Systems in Educationhttps://jaredknowles.com/posts/on-early-warning-systems-in-education/2014-12-12T03:43:37Z2014-12-12T03:43:37ZRecently the NPR program Marketplace did a story about the rise of the use of dropout early warning systems in public schools that you can read or listen to online. I was lucky enough to be interviewed for the piece because of the role I have played in creating the Wisconsin Dropout Early Warning System . Marketplace did a great job explaining the nuances of how these systems fit into the ways schools and districts work. I wanted to use this as an opportunity just write a few thoughts about early warning systems based on my work in this area.Recently the NPR program Marketplace did a story about the rise of the use of dropout early warning systems in public schools that you can read or listen to online.
I was lucky enough to be interviewed for the piece because of the role I have played in creating the Wisconsin Dropout Early Warning System
. Marketplace
did a great job explaining the nuances of how these systems fit into the ways schools and districts work. I wanted to use this as an opportunity just write a few thoughts about early warning systems based on my work in this area.
Not discussed in the story was the more wonky but important question of how these predictions are obtained. While much academic research discusses the merits of various models in terms of their ability to correctly identify students, there is not as much work done discussing the choice of which system to use in application. By its nature, the problem of identifying dropouts early presents a fundamental trade-off between simplicity and accuracy. When deploying an EWS to educators in the field, then, analysts should focus on not how accurate a model is, but if it is accurate enough to be useful and actionable. Unfortunately, most of the research literature on early warning systems focuses on the accuracy of a specific model and not the question of sufficient accuracy.
Part of the reason for this focus is that each model tended to have its own definition of accuracy. A welcome and recent shift in the field to using ROC curves to measure the trade-off between false-positives and false-negatives now allows for these discussions of simple vs. complex to use a common and robust accuracy metric. (Hat tip to Alex Bowers
for working to provide these metrics for dozens of published early warning indicators.) For example, a recent report by the Chicago Consortium on School Research
(CCSR) demonstrates how simple indicators such as grade 8 GPA and attendance can be used to accurately project whether a student will be on-track in grade 9 or not. Using ROC curves, the CCSR can demonstrate on a common scale how accurate these indicators are relative to other more complex indicators and make a compelling case that in Chicago Public Schools these indicators are sufficiently accurate to merit use.
However, in many cases these simple approaches will not be sufficiently accurate to merit use in decision making in schools. Many middle school indicators in the published literature have true dropout identification rates that are quite low, and false-positive rates that are quite high (Bowers, Sprott and Taff 2013
). Furthermore, local conditions may mean that a linkage between GPA and dropout that holds in Chicago Public Schools is not nearly as predictive in another context. Additionally, though not empirically testable in most cases, many EWS indicator systems simply serve to provide a numeric account of information that is apparent to schools in other ways – that is, the indicators selected identify only “obvious” cases of students at risk of dropping out. In this case the overhead of collecting data and conducting identification using the model does not generate a payoff of new actionable information with which to intervene.
More complex models have begun to see use perhaps in part to respond to the challenge of providing value added beyond simple checklist indicators. Unlike checklist or indicator systems, machine learning approaches determine the risk factors empirically from historical data. Instead of asserting that an attendance rate above 95% is necessary to be on-track to graduate, a machine learning algorithm identifies the attendance rate cutoff that that best predicts successful graduation. Better still, the algorithm can do this while jointly considering several other factors simultaneously. This approach is the approach I have previously written about taking in Wisconsin
, and has also been developed in Montgomery County Public Schools
by Data Science for Social Good fellows
.
In fact, the machine learning model is much more flexible than a checklist approach. Once you have moved away from the desire to provide simple indicators that can be applied by users on the fly, and are willing to deliver analytics much like another piece of data, the sky is the limit. Perhaps the biggest advantage to users is that machine learning approaches allow analysts to help schools understand the degree of student risk. Instead of providing a simple yes or no indicator, these approaches can assign probabilities to student completion, allowing the school to use this information to decide on the appropriate level of response.
This concept of degree is important because not all dropouts are simply the lowest performing students in their respective classes. While low performing students do represent a majority of dropouts in many schools, these students are often already identified and being served because of their low-performance. A true early warning system, then, should seek to identify both students who are already identified by schools and those students who are likely non-completers, but who may not already be receiving intervention services. To live up to their name, early warning systems should identify students earlier than after they have started showing acute signs of low performance or disengagement in school. This is where the most value can be delivered to schools.
Despite the improvements possible with a machine learning approach, a lot of work remains to be done. One issue that was raised in the piece in the Marketplace story is understanding how schools put this information to work. An EWS alone will not improve outcomes for students – it only enables schools more time to make changes. There has not been much research on how schools use information like an early warning system to make decisions about students. There needs to be more work done to understand how schools as organizations respond to analytics like early warning indicators. What are their misconceptions? How do they work together? What are the barriers to trusting these more complex calculations and the data that underlie them?
The drawback of the machine learning approach, as the authors of the CCSR report note, is that the results are not intuitive to school staff and this makes the resulting intervention strategy seem less clear. This trade-off strikes at the heart of the changing ways in which data analysis is assisting humans in making decisions. The lack of transparency in the approach must be balanced by an effort on the part of the analysts providing the prediction to communicate the results. Communication can make the results easier to interpret, can build trust in the underlying data, and build capacity within organizations to create the feedback loops necessary to sustain the system. Analysts must actively seek out feedback on the performance of the model, learn where users are struggling to understand it, and where users are finding it clash with their own observations. This is a critical piece in ensuring that the trade-off in complexity does not undermine the usefulness of the entire system.
EWS work represents just the beginning for meaningful analytics to replace the deluge of data in K-12 schools. Schools don’t need more data, they need actionable information that reduces the time not spent on instruction and student services. Analysts don’t need more student data, they need meaningful feedback loops with educators who are tasked with interpreting these analyses and applying the interventions to drive real change. As more work is done to integrate machine learning and eased data collection into the school system, much more work must be done to understand the interface between school organizations, individual educators, and analytics. Analysts and educators must work together to continually refine what information schools and teachers need to be successful and how best to deliver that information in an easy to use fashion at the right time.
]]>
{
"attach_link": true,
"format_string": "{{title}}\n\n{{summary}}",
"og_description": "Recently the NPR program Marketplace did a story about the rise of the use of dropout early warning systems in public schools that you can read or listen to online. I was lucky enough to be interviewed for the piece because of the role I have played in creating the Wisconsin Dropout Early Warning System . Marketplace did a great job explaining the nuances of how these systems fit into the ways schools and districts work. I wanted to use this as an opportunity just write a few thoughts about early warning systems based on my work in this area.",
"og_image": "https://jaredknowles.com/og/posts/on-early-warning-systems-in-education.png",
"og_title": "On Early Warning Systems in Education"
}
Launching DATA-COPEhttps://jaredknowles.com/posts/launching-data-cope/2014-08-28T21:25:52Z2014-08-28T21:25:52ZReally excited to launch my new website - DATA-COPE , a place for education data analysts to share ideas, learn about the latest tools and policies affecting their work, and to keep the pulse on education analytics and the role they play in improving education outcomes. The group is a loosely organized affiliation of state and local education analysts in the United States as well as external researchers at research organizations which provides support to such agencies. The group’s aim is to better learn from one another, share resources, and keep the pulse on any policy or technology related developments that may significantly impact our shared work.Really excited to launch my new website - DATA-COPE
, a place for education data analysts to share ideas, learn about the latest tools and policies affecting their work, and to keep the pulse on education analytics and the role they play in improving education outcomes. The group is a loosely organized affiliation of state and local education analysts in the United States as well as external researchers at research organizations which provides support to such agencies. The group’s aim is to better learn from one another, share resources, and keep the pulse on any policy or technology related developments that may significantly impact our shared work.
My first major post
on the website covers selecting an analytics platform and software suite to best meet the needs of your agency. Spoiler alert, I’m a big fan of R!
]]>
{
"attach_link": true,
"format_string": "{{title}}\n\n{{summary}}",
"og_description": "Really excited to launch my new website - DATA-COPE , a place for education data analysts to share ideas, learn about the latest tools and policies affecting their work, and to keep the pulse on education analytics and the role they play in improving education outcomes. The group is a loosely organized affiliation of state and local education analysts in the United States as well as external researchers at research organizations which provides support to such agencies. The group’s aim is to better learn from one another, share resources, and keep the pulse on any policy or technology related developments that may significantly impact our shared work.",
"og_image": "https://jaredknowles.com/og/posts/launching-data-cope.png",
"og_title": "Launching DATA-COPE"
}
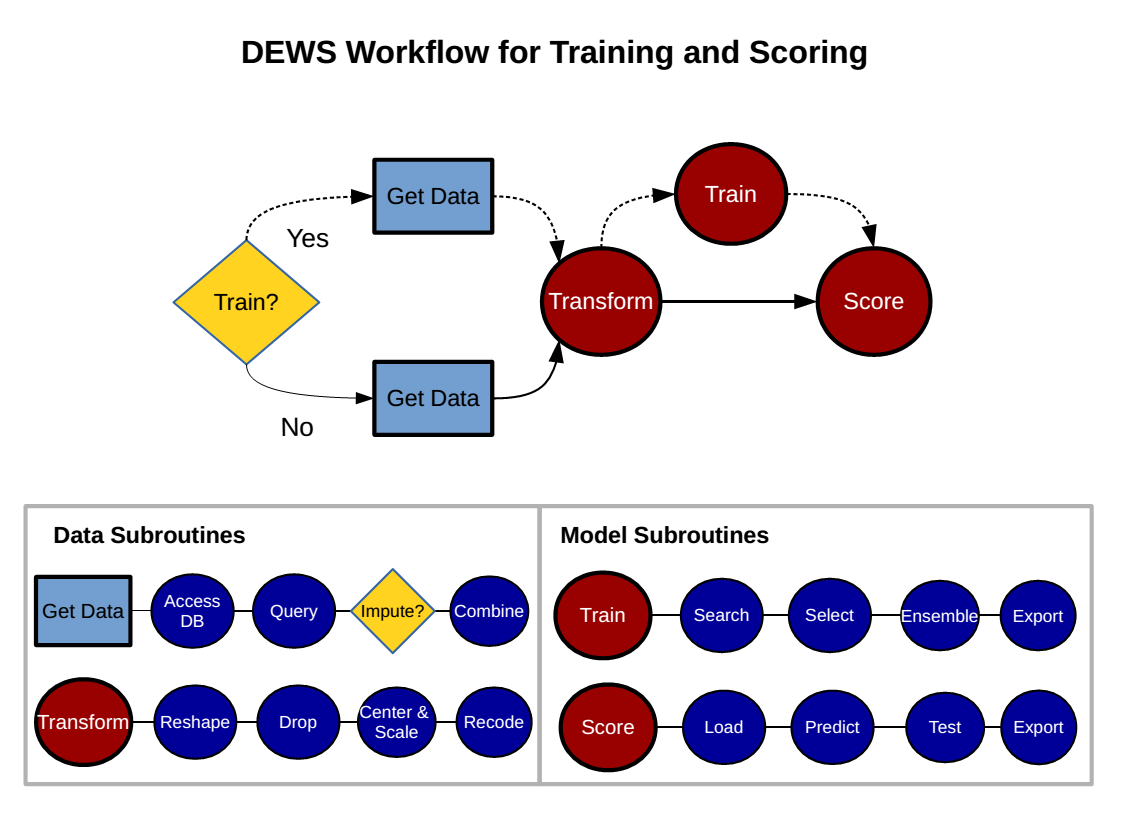
Of Needles and Haystacks: Building an Accurate Statewide Dropout Early Warning System in Wisconsinhttps://jaredknowles.com/posts/of-needles-and-haystacks-building-an-accurate-statewide-dropout-early-warning-system-in-wisconsin/2014-08-25T15:35:02Z2014-08-25T15:35:02ZFor the past two years I have been working on the Wisconsin Dropout Early Warning System, a predictive model of on time high school graduation for students in grades 6-9 in Wisconsin. The goal of this project is to help schools and educators have an early indication of the likely graduation of each of their students, early enough to allow time for individualized intervention. The result is that nearly 225,000 students receive an individualized prediction at the start and end of the school year. The workflow for the system is mapped out in the diagram below:For the past two years I have been working on the Wisconsin Dropout Early Warning System, a predictive model of on time high school graduation for students in grades 6-9 in Wisconsin. The goal of this project is to help schools and educators have an early indication of the likely graduation of each of their students, early enough to allow time for individualized intervention. The result is that nearly 225,000 students receive an individualized prediction at the start and end of the school year. The workflow for the system is mapped out in the diagram below:
View fullsize
The system is moving into its second year of use this fall and I recently completed a research paper describing the predictive analytic approach taken within DEWS. The research paper is intended to serve as a description and guide of the decisions made in developing an automated prediction system using administrative data. The paper covers both the data preparation and model building process as well as a review of the results. A preview is shown below which demonstrates how the EWS models trained in Wisconsin compare to the accuracy reported in the research literature - represented by the points on the graph. The accuracy is measured using the ROC curve. The article is now available via figshare.
View fullsize
The colored lines represent different types of ensembled statistical models and their accuracy across various thresholds of their predicted probabilities. The points represent the accuracy of comparable models in the research literature using reported accuracy from a paper by Alex Bowers
:
Bowers, A.J., Sprott, R.*, Taff, S.A.* (2013) Do we Know Who Will Drop Out? A Review of the Predictors of Dropping out of High School: Precision, Sensitivity and Specificity. The
High School Journal, 96(2), 77-100. doi:10.1353/hsj.2013.0000
. This article serves as good background and grounds the benchmarking of the models built in Wisconsin and for others when benchmarking their own models.
Article Abstract:
The state of Wisconsin has one of the highest four year graduation rates in the nation, but deep disparities among student subgroups remain. To address this the state has created the Wisconsin Dropout Early Warning System (DEWS), a predictive model of student dropout risk for students in grades six through nine. The Wisconsin DEWS is in use statewide and currently provides predictions on the likelihood of graduation for over 225,000 students. DEWS represents a novel statistical learning based approach to the challenge of assessing the risk of non-graduation for students and provides highly accurate predictions for students in the middle grades without expanding beyond mandated administrative data collections.
Similar dropout early warning systems are in place in many jurisdictions across the country. Prior research has shown that in many cases the indicators used by such systems do a poor job of balancing the trade off between correct classification of likely dropouts and false-alarm (Bowers et al., 2013). Building on this work, DEWS uses the receiver-operating characteristic (ROC) metric to identify the best possible set of statistical models for making predictions about individual students.
This paper describes the DEWS approach and the software behind it, which leverages the open source statistical language R (R Core Team, 2013). As a result DEWS is a flexible series of software modules that can adapt to new data, new algorithms, and new outcome variables to not only predict dropout, but also impute key predictors as well. The design and implementation of each of these modules is described in detail as well as the open-source R package, EWStools, that serves as the core of DEWS (Knowles, 2014).
Code:
The code that powers the EWS is an open source R extension of the caret package which is available on GitHub: EWStools on GitHub
]]>
{
"attach_link": true,
"format_string": "{{title}}\n\n{{summary}}",
"og_description": "For the past two years I have been working on the Wisconsin Dropout Early Warning System, a predictive model of on time high school graduation for students in grades 6-9 in Wisconsin. The goal of this project is to help schools and educators have an early indication of the likely graduation of each of their students, early enough to allow time for individualized intervention. The result is that nearly 225,000 students receive an individualized prediction at the start and end of the school year. The workflow for the system is mapped out in the diagram below:",
"og_image": "https://jaredknowles.com/og/posts/of-needles-and-haystacks-building-an-accurate-statewide-dropout-early-warning-system-in-wisconsin.png",
"og_title": "Of Needles and Haystacks: Building an Accurate Statewide Dropout Early Warning System in Wisconsin"
}
Mixed Effects Tutorial 2: Fun with merMod Objectshttps://jaredknowles.com/posts/mixed-effects-tutorial-2-fun-with-mermod-objects/2014-05-17T22:38:18Z2014-05-17T22:38:18ZUpdate: Since this post was released I have co-authored an R package to make some of the items in this post easier to do. This package is called merTools and is available on CRAN and on GitHub. To read more about it, read my new pos t here and check out the packageon GitHub . Introduction # First of all, be warned, the terminology surrounding multilevel models is vastly inconsistent. For example, multilevel models themselves may be referred to as hierarchical linear models, random effects models, multilevel models, random intercept models, random slope models, or pooling models. Depending on the discipline, software used, and the academic literature many of these terms may be referring to the same general modeling strategy. In this tutorial I will attempt to provide a user guide to multilevel modeling by demonstrating how to fit multilevel models in R and by attempting to connect the model fitting procedure to commonly used terminology used regarding these models.Update: Since this post was released I have co-authored an R package to make some of the items in this post easier to do. This package is called merTools and is available on CRAN and on GitHub. To read more about it, read my new post here and
check out the packageon GitHub
.
First of all, be warned, the terminology surrounding multilevel models is vastly inconsistent. For
example, multilevel models themselves may be referred to as hierarchical linear models, random
effects models, multilevel models, random intercept models, random slope models, or pooling models.
Depending on the discipline, software used, and the academic literature many of these terms may be
referring to the same general modeling strategy. In this tutorial I will attempt to provide a user
guide to multilevel modeling by demonstrating how to fit multilevel models in R and by attempting to
connect the model fitting procedure to commonly used terminology used regarding these models.
We will cover the following topics:
The structure and methods of merMod objects
Extracting random effects of merMod objects
Plotting and interpreting merMod objects
If you haven’t already, make sure you head over to the Getting Started With Multilevel Models
tutorial
in order to ensure you have set up your environment correctly and installed all the necessary
packages. The tl;dr is that you will need:
Multilevel models are appropriate for a particular kind of data structure where units are nested
within groups (generally 5+ groups) and where we want to model the group structure of the data. For
our introductory example we will start with a simple example from the lme4 documentation and
explain what the model is doing. We will use data from Jon Starkweather at the University of North
Texas
. Visit the excellent tutorial
available here for
more.
library(lme4)# load librarylibrary(arm)# convenience functions for regression in Rlmm.data<-read.table("http://bayes.acs.unt.edu:8083/BayesContent/class/Jon/R_SC/Module9/lmm.data.txt",header=TRUE,sep=",",na.strings="NA",dec=".",strip.white=TRUE)#summary(lmm.data)head(lmm.data)## id extro open agree social class school## 1 1 63.69356 43.43306 38.02668 75.05811 d IV## 2 2 69.48244 46.86979 31.48957 98.12560 a VI## 3 3 79.74006 32.27013 40.20866 116.33897 d VI## 4 4 62.96674 44.40790 30.50866 90.46888 c IV## 5 5 64.24582 36.86337 37.43949 98.51873 d IV## 6 6 50.97107 46.25627 38.83196 75.21992 d I
Here we have data on the extroversion of subjects nested within classes and within schools.
Let’s understand the structure of the data a bit before we begin:
Here we see we have two possible grouping variables – class and school. Let’s
explore them a bit further:
table(lmm.data$class)## ## a b c d ## 300 300 300 300
table(lmm.data$school)## ## I II III IV V VI ## 200 200 200 200 200 200
table(lmm.data$class,lmm.data$school)## ## I II III IV V VI## a 50 50 50 50 50 50## b 50 50 50 50 50 50## c 50 50 50 50 50 50## d 50 50 50 50 50 50
This is a perfectly balanced dataset. In all likelihood you aren’t working with a perfectly balanced
dataset, but we’ll explore the implications for that in the future. For now, let’s plot the data a
bit. Using the excellent xyplot function in the lattice package, we can explore the relationship
between schools and classes across our variables.
require(lattice)xyplot(extro~open+social+agree|class,data=lmm.data,auto.key=list(x=.85,y=.035,corner=c(0,0)),layout=c(4,1),main="Extroversion by Class")
Here we see that within classes there are clear stratifications and we also see that the social
variable is strongly distinct from the open and agree variables. We also see that class a and
class d have significantly more spread in their lowest and highest bands respectively. Let’s next
plot the data by school.
xyplot(extro~open+social+agree|school,data=lmm.data,auto.key=list(x=.85,y=.035,corner=c(0,0)),layout=c(3,2),main="Extroversion by School")
By school we see that students are tightly grouped, but that school I and school VI show
substantially more dispersion than the other schools. The same pattern among our predictors holds
between schools as it did between classes. Let’s put it all together:
xyplot(extro~open+social+agree|school+class,data=lmm.data,auto.key=list(x=.85,y=.035,corner=c(0,0)),main="Extroversion by School and Class")
Here we can see that school and class seem to closely differentiate the relationship between our
predictors and extroversion.
In the last tutorial we fit a series of random intercept models to our nested data. We will examine
the lmerMod object produced when we fit this model in much more depth in order to understand how
to work with mixed effect models in R. We start by fitting a the basic example below grouped by
class:
First, we see that MLexamp1 is now an R object of the class lmerMod. This lmerMod object is an
S4 class, and to explore its structure, we use slotNames:
Within the lmerMod object we see a number of objects that we may wish to explore. To look at any
of these, we can simply type MLexamp1@ and then the slot name itself. For example:
MLexamp1@call# returns the model call## lmer(formula = extro ~ open + agree + social + (1 | school), ## data = lmm.data)
MLexamp1@beta# returns the betas## [1] 59.116514199 0.009750941 0.027788360 -0.002151446
class(MLexamp1@frame)# returns the class for the frame slot## [1] "data.frame"
head(MLexamp1@frame)# returns the model frame## extro open agree social school## 1 63.69356 43.43306 38.02668 75.05811 IV## 2 69.48244 46.86979 31.48957 98.12560 VI## 3 79.74006 32.27013 40.20866 116.33897 VI## 4 62.96674 44.40790 30.50866 90.46888 IV## 5 64.24582 36.86337 37.43949 98.51873 IV## 6 50.97107 46.25627 38.83196 75.21992 I
The merMod object has a number of methods available – too many to enumerate here. But, we will go
over some of the more common in the list below:
A common need is to extract the fixed effects from a merMod object. fixef extracts a named
numeric vector of the fixed effects, which is handy.
fixef(MLexamp1)## (Intercept) open agree social ## 59.116514199 0.009750941 0.027788360 -0.002151446
If you want to get a sense of the p-values or statistical significance of these parameters, first
consult the lme4 help by running ?mcmcsamp for a rundown of various ways of doing this. One
convenient way built into the package is:
From here we can see first that our fixed effect parameters overlap 0 indicating no evidence of an
effect. We can also see that .sig01, which is our estimate of the variability in the random
effect, is very large and very widely defined. This indicates we may have a lack of precision
between our groups - either because the group effect is small between groups, we have too few groups
to get a more precise estimate, we have too few units within each group, or a combination of all of
the above.
Another common need is to extract the residual standard error, which is necessary for calculating
effect sizes. To get a named vector of the residual standard error:
sigma(MLexamp1)## [1] 2.670886
For example, it is common practice in education research to standardize fixed effects into “effect
sizes” by dividing the fixed effect paramters by the residual standard error, which can be
accomplished in lme4 easily:
fixef(MLexamp1)/sigma(MLexamp1)## (Intercept) open agree social ## 22.1336707437 0.0036508262 0.0104041726 -0.0008055176
From this, we can see that our predictors of openness, agreeableness and social are virtually
useless in predicting extroversion – as our plots showed. Let’s turn our attention to the random
effects next.
In all likelihood you fit a mixed-effect model because you are directly interested in the
group-level variation in your model. It is not immediately clear how to explore this group level
variation from the results of summary.merMod. What we get from this output is the variance and the
standard deviation of the group effect, but we do not get effects for individual groups. This is
where the ranef function comes in handy.
ranef(MLexamp1)## $school## (Intercept)## I -14.090991## II -6.183368## III -1.970700## IV 1.965938## V 6.330710## VI 13.948412## ## with conditional variances for "school"
Running the ranef function gives us the intercepts for each school, but not much additional
information – for example the precision of these estimates. To do that, we need some additional
commands:
re1<-ranef(MLexamp1,condVar=TRUE)# save the ranef.mer objectclass(re1)## [1] "ranef.mer"
The ranef.mer object is a list which contains a data.frame for each group level. The dataframe
contains the random effects for each group (here we only have an intercept for each school). When we
ask lme4 for the conditional variance of the random effects it is stored in an attribute of
those dataframes as a list of variance-covariance matrices.
This structure is indeed complicated, but it is powerful as it allows for nested, grouped, and
cross-level random effects. Also, the creators of lme4 have provided users with some simple
shortcuts to get what they are really interested in out of a ranef.mer object.
re1<-ranef(MLexamp1,condVar=TRUE,whichel="school")print(re1)## $school## (Intercept)## I -14.090991## II -6.183368## III -1.970700## IV 1.965938## V 6.330710## VI 13.948412## ## with conditional variances for "school"
dotplot(re1)## $school
This graphic shows a dotplot of the random effect terms, also known as a caterpillar plot. Here
you can clearly see the effects of each school on extroversion as well as their standard errors to
help identify how distinct the random effects are from one another. Interpreting random effects is
notably tricky, but for assistance I would recommend looking at a few of these resources:
John Fox - An R Compantion to Applied Regression web appendix
Using Simulation and Plots to Explore Random Effects#
A common econometric approach is to create what are known as empirical Bayes estimates of the
group-level terms. Unfortunately there is not much agreement about what constitutes a proper
standard error for the random effect terms or even how to consistently define empirical Bayes
estimates.1 However, in R there are a few additional ways to get estimates of the random effects
that provide the user with information about the relative sizes of the effects for each unit and the
precision in that estimate. To do this, we use the sim function in the arm package.2
# A function to extract simulated estimates of random effect paramaters from # lme4 objects using the sim function in arm# whichel = the character for the name of the grouping effect to extract estimates for # nsims = the number of simulations to pass to sim# x = model objectREsim<-function(x,whichel=NULL,nsims){require(plyr)mysim<-sim(x,n.sims=nsims)if(missing(whichel)){dat<-plyr::adply(mysim@ranef[[1]],c(2,3),plyr::each(c(mean,median,sd)))warning("Only returning 1st random effect because whichel not specified")}else{dat<-plyr::adply(mysim@ranef[[whichel]],c(2,3),plyr::each(c(mean,median,sd)))}return(dat)}REsim(MLexamp1,whichel="school",nsims=1000)## X1 X2 mean median sd## 1 I (Intercept) -14.133834 -14.157333 3.871655## 2 II (Intercept) -6.230981 -6.258464 3.873329## 3 III (Intercept) -2.011822 -2.034863 3.872661## 4 IV (Intercept) 1.915608 1.911129 3.866870## 5 V (Intercept) 6.282461 6.299311 3.867046## 6 VI (Intercept) 13.901818 13.878827 3.873950
The REsim function returns for each school the level name X1, the estimate name, X2, the mean
of the estimated values, the median, and the standard deviation of the estimates.
Another convenience function can help us plot these results to see how they compare to the results
of dotplot:
# Dat = results of REsim# scale = factor to multiply sd by# var = character of "mean" or "median"# sd = character of "sd"plotREsim<-function(dat,scale,var,sd){require(eeptools)dat[,sd]<-dat[,sd]*scaledat[,"ymax"]<-dat[,var]+dat[,sd]dat[,"ymin"]<-dat[,var]-dat[,sd]dat[order(dat[,var]),"id"]<-c(1:nrow(dat))ggplot(dat,aes_string(x="id",y=var,ymax="ymax",ymin="ymin"))+geom_pointrange()+theme_dpi()+labs(x="Group",y="Effect Range",title="Effect Ranges")+theme(panel.grid.major=element_blank(),panel.grid.minor=element_blank(),axis.text.x=element_blank(),axis.ticks.x=element_blank())+geom_hline(yintercept=0,color=I("red"),size=I(1.1))}plotREsim(REsim(MLexamp1,whichel="school",nsims=1000),scale=1.2,var="mean",sd="sd")
This presents a more conservative view of the variation between random effect components. Depending
on how your data was collected and your research question, alternative ways of estimating these
effect sizes are possible. However, proceed with caution.3
Another approach recommended by the authors of lme4 involves the RLRsim package. Using this
package we can test whether or not inclusion of the random effects improves model fit and we can
evaluate the p-value of additional random effect terms using a likelihood ratio test based on
simulation.4
library(RLRsim)m0<-lm(extro~agree+open+social,data=lmm.data)# fit the null modelexactLRT(m=MLexamp1,m0=m0)## ## simulated finite sample distribution of LRT. (p-value based on 10000 simulated values)## ## data: ## LRT = 2957.7, p-value < 2.2e-16
Here exactLRT issues a warning because we originally fit the model with REML instead of full
maximum likelihood. Fortunately, the refitML function in lme4 allows us to easily refit our
model using full maximum likelihood to conduct an exact test easily.
mA<-refitML(MLexamp1)exactLRT(m=mA,m0=m0)## ## simulated finite sample distribution of LRT. (p-value based on 10000 simulated values)## ## data: ## LRT = 2957.8, p-value < 2.2e-16
Here we can see that the inclusion of our grouping variable is significant, even though the effect
of each individual group may be substantively small and/or imprecisely measured. This is important
in understanding the correct specification of the model. Our next tutorial will cover specification
tests like this in more detail.
How do interpret the substantive impact of our random effects? This is often critical in
observation work trying to use a multilevel structure to understand the impact that the grouping can
have on the individual observation. To do this we select 12 random cases and then we simulate their
predicted value of extro if they were placed in each of the 6 schools. Note, that this is a very
simple simulation just using the mean of the fixed effect and the conditional mode of the random
effect and not replicating or sampling to get a sense of the variability. This will be left as an
exercise to the reader and/or a future tutorial!
# Simulate# Let's create 12 cases of students# #sample some rowssimX<-sample(lmm.data$id,12)simX<-lmm.data[lmm.data$id%in%simX,c(3:5)]# get their data# add an interceptsimX[,"Intercept"]<-1simX<-simX[,c(4,1:3)]# reordersimRE<-REsim(MLexamp1,whichel="school",nsims=1000)# simulate randome effectssimX$case<-row.names(simX)# create a case ID# expand a grid of case IDs by schoolssimDat<-expand.grid(case=row.names(simX),school=levels(lmm.data$school))simDat<-merge(simX,simDat)# merge in the data# Create the fixed effect predictorsimDat[,"fepred"]<-(simDat[,2]*fixef(MLexamp1)[1])+(simDat[,3]*fixef(MLexamp1)[2])+(simDat[,4]*fixef(MLexamp1)[3])+(simDat[,5]*fixef(MLexamp1)[4])# Add the school effectssimDat<-merge(simDat,simRE[,c(1,3)],by.x="school",by.y="X1")simDat$yhat<-simDat$fepred+simDat$mean# add the school specific intercept
Now that we have set up a simulated dataframe, let’s plot it, first by case:
This plot shows us that within each plot, representing a case, there is tremendous variation by
school. So, moving each student into a different school has large effects on the extroversion score.
But, does each case vary at each school?
Here we can clearly see that within each school the cases are relatively the same indicating that
the group effect is larger than the individual effects.
These plots are useful in demonstrating the relative importance of group and individual effects in a
substantive fashion. Even more can be done to make the the graphs more informative, such as placing
references to the total variability of the outcome and also looking at the distance moving groups
moves each observation from its true value.
lme4 provides a very powerful object-oriented toolset for dealing with mixed effect models in R.
Understanding model fit and confidence intervals of lme4 objects requires some diligent research
and the use of a variety of functions and extensions of lme4 itself. In our next tutorial we will
explore how to identify a proper specification of a random-effect model and Bayesian extensions of
the lme4 framework for difficult to specify models. We will also explore the generalized linear
model framework and the glmer function for generalized linear modeling with multi-levels.
Andrew Gelman and Yu-Sung Su (2014). arm: Data Analysis Using Regression and Multilevel/Hierarchical Models. R package version
1.7-03. http://CRAN.R-project.org/package=arm↩︎
There are also an extensive series of references available in the References
section of the help by running ?exactLRT and ?exactRLRT. ↩︎
]]>
{
"attach_link": true,
"format_string": "{{title}}\n\n{{summary}}",
"og_description": "Update: Since this post was released I have co-authored an R package to make some of the items in this post easier to do. This package is called merTools and is available on CRAN and on GitHub. To read more about it, read my new pos t here and check out the packageon GitHub . Introduction # First of all, be warned, the terminology surrounding multilevel models is vastly inconsistent. For example, multilevel models themselves may be referred to as hierarchical linear models, random effects models, multilevel models, random intercept models, random slope models, or pooling models. Depending on the discipline, software used, and the academic literature many of these terms may be referring to the same general modeling strategy. In this tutorial I will attempt to provide a user guide to multilevel modeling by demonstrating how to fit multilevel models in R and by attempting to connect the model fitting procedure to commonly used terminology used regarding these models.",
"og_image": "https://jaredknowles.com/og/posts/mixed-effects-tutorial-2-fun-with-mermod-objects.png",
"og_title": "Mixed Effects Tutorial 2: Fun with merMod Objects"
}
eeptools 0.3 Released!https://jaredknowles.com/posts/eeptools-03-released/2013-12-10T05:31:03Z2013-12-10T05:31:03ZVersion 0.3 of my R package of miscellaneous code has been released, this time with substantial contributions from Jason Becker via GitHub. Progress continues toward the ultimate goal for eeptools to “make it easier for administrators at state and local education agencies to analyze and visualize their data on student, school, and district performance. By putting simple wrappers around a number of R functions to make many common tasks simpler and lower the barrier to entry to statistical analysis.Version 0.3 of my R package of miscellaneous code has been released, this time with substantial contributions from Jason Becker
via GitHub. Progress continues toward the ultimate goal for eeptools to “make it easier for administrators at state and local education agencies to analyze and visualize their data on student, school, and district performance. By putting simple wrappers around a number of R functions to make many common tasks simpler and lower the barrier to entry to statistical analysis.
The goal is not to invent new functionality for R, but instead to lower the barrier of entry to doing common and routine data manipulation, visualization, and analysis tasks with education data. By collaborating with other users of education data we can build transparent, efficient, reproducible, and easy to use functions for analysts.
Suggestions and pull requests are very welcome on GitHub
.
See the NEWS file in the repository for full updates:
eeptools0.3
* unit tests for decomma, gelmansim, and statamode using testthat package
* statamode updated to work with data.table
* age_calc function from Jason Becker given new precision option
* moves_calc function from Jason Becker
* gelmansim function to do post-estimation prediction on new data from model objects using functionality in the arm package
* lag_data function to create groupwise nested lags quickly
eeptools 0.2
* new functions for building maps with shapefiles including mapmerge to merge a dataframe and a shapefile, and ggmapmerge to conver this to a document for making a map in ggplot2
* statamode updated to allow for multiple methods for handling multiple modes
* remove_stars deleted and replaced with remove_char to allow for users to specify an arbitrary character string to be removed
* add plotForWord function to export plots in a Windows MetaFile for inclusion in Microsoft Office documents
* add age_calc function to allow calculating the age of a vector of birthdates relative to the current date
* fix typos in documentation
* fix startup message behavior
* remove dependencies of the package dramatically so loading is faster and more lightweight
]]>
{
"attach_link": true,
"format_string": "{{title}}\n\n{{summary}}",
"og_description": "Version 0.3 of my R package of miscellaneous code has been released, this time with substantial contributions from Jason Becker via GitHub. Progress continues toward the ultimate goal for eeptools to “make it easier for administrators at state and local education agencies to analyze and visualize their data on student, school, and district performance. By putting simple wrappers around a number of R functions to make many common tasks simpler and lower the barrier to entry to statistical analysis.",
"og_image": "https://jaredknowles.com/og/posts/eeptools-03-released.png",
"og_title": "eeptools 0.3 Released!"
}
Getting Started with Mixed Effect Models in Rhttps://jaredknowles.com/posts/getting-started-with-mixed-effect-models-in-r/2013-11-25T19:47:35Z2013-11-25T19:47:35ZUpdate: Since this post was released I have co-authored an R package to make some of the items in this post easier to do. This package is called merTools and is available on CRAN and on GitHub. To read more about it, read my new post h ere and check out the package on GitHub . Introduction # Analysts dealing with grouped data and complex hierarchical structures in their data ranging from measurements nested within participants, to counties nested within states or students nested within classrooms often find themselves in need of modeling tools to reflect this structure of their data. In R there are two predominant ways to fit multilevel models that account for such structure in the data. These tutorials will show the user how to use both the lme4 package in R to fit linear and nonlinear mixed effect models, and to use rstan to fit fully Bayesian multilevel models. The focus here will be on how to fit the models in R and not the theory behind the models. For background on multilevel modeling, see the references. [1]Update: Since this post was released I have co-authored an R package to make some of the items in this post easier to do. This package is called merTools and is available on CRAN and on GitHub. To read more about it, read my new post here and check
out the package on GitHub
.
Analysts dealing with grouped data and complex hierarchical structures in their data ranging from
measurements nested within participants, to counties nested within states or students nested within
classrooms often find themselves in need of modeling tools to reflect this structure of their data.
In R there are two predominant ways to fit multilevel models that account for such structure in the
data. These tutorials will show the user how to use both the lme4 package in R to fit linear and
nonlinear mixed effect models, and to use rstan to fit fully Bayesian multilevel models. The focus
here will be on how to fit the models in R and not the theory behind the models. For background on
multilevel modeling, see the references. [1]
This tutorial will cover getting set up and running a few basic models using lme4 in R. Future
tutorials will cover:
constructing varying intercept, varying slope, and varying slope and intercept models in R
generating predictions and interpreting parameters from mixed-effect models
generalized and non-linear multilevel models
fully Bayesian multilevel models fit with rstan or other MCMC methods
Getting started with multilevel modeling in R is simple. lme4 is the canonical package for
implementing multilevel models in R, though there are a number of packages that depend on and
enhance its feature set, including Bayesian extensions. lme4 has been recently rewritten to
improve speed and to incorporate a C++ codebase, and as such the features of the package are
somewhat in flux. Be sure to update the package frequently.
To install lme4, we just run:
# Main versioninstall.packages("lme4")# Or to install the dev versionlibrary(devtools)install_github("lme4",user="lme4")
Multilevel models are appropriate for a particular kind of data structure where units are nested
within groups (generally 5+ groups) and where we want to model the group structure of the data. For
our introductory example we will start with a simple example from the lme4 documentation and
explain what the model is doing. We will use data from Jon Starkweather at the University of North
Texas
. Visit the excellent tutorial
available here for
more.
library(lme4)# load librarylibrary(arm)# convenience functions for regression in Rlmm.data<-read.table("http://bayes.acs.unt.edu:8083/BayesContent/class/Jon/R_SC/Module9/lmm.data.txt",header=TRUE,sep=",",na.strings="NA",dec=".",strip.white=TRUE)#summary(lmm.data)head(lmm.data)## id extro open agree social class school## 1 1 63.69356 43.43306 38.02668 75.05811 d IV## 2 2 69.48244 46.86979 31.48957 98.12560 a VI## 3 3 79.74006 32.27013 40.20866 116.33897 d VI## 4 4 62.96674 44.40790 30.50866 90.46888 c IV## 5 5 64.24582 36.86337 37.43949 98.51873 d IV## 6 6 50.97107 46.25627 38.83196 75.21992 d I
Here we have data on the extroversion of subjects nested within classes and within schools.
Let’s start by fitting a simple OLS regression of measures of openness, agreeableness, and
socialability on extroversion. Here we use the display function in the excellent arm package for
abbreviated output. Other options include stargazer for LaTeX typeset tables, xtable, or the
ascii package for more flexible plain text output options.
OLSexamp<-lm(extro~open+agree+social,data=lmm.data)display(OLSexamp)## lm(formula = extro ~ open + agree + social, data = lmm.data)## coef.est coef.se## (Intercept) 57.84 3.15 ## open 0.02 0.05 ## agree 0.03 0.05 ## social 0.01 0.02 ## ---## n = 1200, k = 4## residual sd = 9.34, R-Squared = 0.00
So far this model does not fit very well at all. The R model interface is quite a simple one with
the dependent variable being specified first, followed by the ~ symbol. The righ hand side,
predictor variables, are each named. Addition signs indicate that these are modeled as additive
effects. Finally, we specify that datframe on which to calculate the model. Here we use the lm
function to perform OLS regression, but there are many other options in R.
If we want to extract measures such as the AIC, we may prefer to fit a generalized linear model with
glm which produces a model fit through maximum likelihood estimation. Note that the model formula
specification is the same.
MLexamp<-glm(extro~open+agree+social,data=lmm.data)display(MLexamp)## glm(formula = extro ~ open + agree + social, data = lmm.data)## coef.est coef.se## (Intercept) 57.84 3.15 ## open 0.02 0.05 ## agree 0.03 0.05 ## social 0.01 0.02 ## ---## n = 1200, k = 4## residual deviance = 104378.2, null deviance = 104432.7 (difference = 54.5)## overdispersion parameter = 87.3## residual sd is sqrt(overdispersion) = 9.34
AIC(MLexamp)## [1] 8774.291
This results in a poor model fit. Let’s look at a simple varying intercept model now.
Depending on disciplinary norms, our next step might be to fit a varying intercept model using a
grouping variable such as school or classes. Using the glm function and the familiar formula
interface, such a fit is easy:
MLexamp.2<-glm(extro~open+agree+social+class,data=lmm.data)display(MLexamp.2)## glm(formula = extro ~ open + agree + social + class, data = lmm.data)## coef.est coef.se## (Intercept) 56.05 3.09 ## open 0.03 0.05 ## agree -0.01 0.05 ## social 0.01 0.02 ## classb 2.06 0.75 ## classc 3.70 0.75 ## classd 5.67 0.75 ## ---## n = 1200, k = 7## residual deviance = 99187.7, null deviance = 104432.7 (difference = 5245.0)## overdispersion parameter = 83.1## residual sd is sqrt(overdispersion) = 9.12
AIC(MLexamp.2)## [1] 8719.083
anova(MLexamp,MLexamp.2,test="F")## Analysis of Deviance Table## ## Model 1: extro ~ open + agree + social## Model 2: extro ~ open + agree + social + class## Resid. Df Resid. Dev Df Deviance F Pr(>F) ## 1 1196 104378 ## 2 1193 99188 3 5190.5 20.81 3.82e-13 ***## ---## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
This is called a fixed-effects specification often. This is simply the case of fitting a separate
dummy variable as a predictor for each class. We can see this does not provide much additional model
fit. Let’s see if school performs any better.
anova(MLexamp,MLexamp.3,test="F")## Analysis of Deviance Table## ## Model 1: extro ~ open + agree + social## Model 2: extro ~ open + agree + social + school## Resid. Df Resid. Dev Df Deviance F Pr(>F) ## 1 1196 104378 ## 2 1191 8496 5 95882 2688.2 < 2.2e-16 ***## ---## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
The school effect greatly improves our model fit. However, how do we interpret these effects?
table(lmm.data$school,lmm.data$class)## ## a b c d## I 50 50 50 50## II 50 50 50 50## III 50 50 50 50## IV 50 50 50 50## V 50 50 50 50## VI 50 50 50 50
Here we can see we have a perfectly balanced design with fifty observations in each combination of
class and school (if only data were always so nice!).
Let’s try to model each of these unique cells. To do this, we fit a model and use the : operator
to specify the interaction between school and class.
This is very useful, but what if we want to understand both the effect of the school and the effect
of the class, as well as the effect of the schools and classes? Unfortunately, this is not easily
done with the standard glm.
Another alternative is to fit a separate model for each of the school and class combinations. If we
believe the relationsihp between our variables may be highly dependent on the school and class
combination, we can simply fit a series of models and explore the parameter variation among them:
require(plyr)modellist<-dlply(lmm.data,.(school,class),function(x)glm(extro~open+agree+social,data=x))display(modellist[[1]])## glm(formula = extro ~ open + agree + social, data = x)## coef.est coef.se## (Intercept) 35.87 5.90 ## open 0.05 0.09 ## agree 0.02 0.10 ## social 0.01 0.03 ## ---## n = 50, k = 4## residual deviance = 500.2, null deviance = 506.2 (difference = 5.9)## overdispersion parameter = 10.9## residual sd is sqrt(overdispersion) = 3.30
display(modellist[[2]])## glm(formula = extro ~ open + agree + social, data = x)## coef.est coef.se## (Intercept) 47.96 2.16 ## open -0.01 0.03 ## agree -0.03 0.03 ## social -0.01 0.01 ## ---## n = 50, k = 4## residual deviance = 47.9, null deviance = 49.1 (difference = 1.2)## overdispersion parameter = 1.0## residual sd is sqrt(overdispersion) = 1.02
We will discuss this strategy in more depth in future tutorials including how to performan inference
on the list of models produced in this command.
Enter lme4. While all of the above techniques are valid approaches to this problem, they are not
necessarily the best approach when we are interested explicitly in variation among and by groups.
This is where a mixed-effect modeling framework is useful. Now we use the lmer function with the
familiar formula interface, but now group level variables are specified using a special syntax:
(1|school) tells lmer to fit a linear model with a varying-intercept group effect using the
variable school.
MLexamp.6<-lmer(extro~open+agree+social+(1|school),data=lmm.data)display(MLexamp.6)## lmer(formula = extro ~ open + agree + social + (1 | school), ## data = lmm.data)## coef.est coef.se## (Intercept) 59.12 4.10 ## open 0.01 0.01 ## agree 0.03 0.02 ## social 0.00 0.00 ## ## Error terms:## Groups Name Std.Dev.## school (Intercept) 9.79 ## Residual 2.67 ## ---## number of obs: 1200, groups: school, 6## AIC = 5836.1, DIC = 5788.9## deviance = 5806.5
We can fit multiple group effects with multiple group effect terms.
MLexamp.7<-lmer(extro~open+agree+social+(1|school)+(1|class),data=lmm.data)display(MLexamp.7)## lmer(formula = extro ~ open + agree + social + (1 | school) + ## (1 | class), data = lmm.data)## coef.est coef.se## (Intercept) 60.20 4.21 ## open 0.01 0.01 ## agree -0.01 0.01 ## social 0.00 0.00 ## ## Error terms:## Groups Name Std.Dev.## school (Intercept) 9.79 ## class (Intercept) 2.41 ## Residual 1.67 ## ---## number of obs: 1200, groups: school, 6; class, 4## AIC = 4737.9, DIC = 4683.3## deviance = 4703.6
And finally, we can fit nested group effect terms through the following syntax:
MLexamp.8<-lmer(extro~open+agree+social+(1|school/class),data=lmm.data)display(MLexamp.8)## lmer(formula = extro ~ open + agree + social + (1 | school/class), ## data = lmm.data)## coef.est coef.se## (Intercept) 60.24 4.01 ## open 0.01 0.00 ## agree -0.01 0.01 ## social 0.00 0.00 ## ## Error terms:## Groups Name Std.Dev.## class:school (Intercept) 2.86 ## school (Intercept) 9.69 ## Residual 0.98 ## ---## number of obs: 1200, groups: class:school, 24; school, 6## AIC = 3568.6, DIC = 3507.6## deviance = 3531.1
Here the (1|school/class) says that we want to fit a mixed effect term for varying intercepts 1|
by schools, and for classes that are nested within schools.
But, what if we want to explore the effect of different student level indicators as they vary across
classrooms. Instead of fitting unique models by school (or school/class) we can fit a varying slope
model. Here we modify our random effect term to include variables before the grouping terms:
(1 +open|school/class) tells R to fit a varying slope and varying intercept model for schools and
classes nested within schools, and to allow the slope of the open variable to vary by school.
MLexamp.9<-lmer(extro~open+agree+social+(1+open|school/class),data=lmm.data)display(MLexamp.9)## lmer(formula = extro ~ open + agree + social + (1 + open | school/class), ## data = lmm.data)## coef.est coef.se## (Intercept) 60.26 3.46 ## open 0.01 0.01 ## agree -0.01 0.01 ## social 0.00 0.00 ## ## Error terms:## Groups Name Std.Dev. Corr ## class:school (Intercept) 2.61 ## open 0.01 1.00 ## school (Intercept) 8.33 ## open 0.00 1.00 ## Residual 0.98 ## ---## number of obs: 1200, groups: class:school, 24; school, 6## AIC = 3574.9, DIC = 3505.6## deviance = 3529.3
Fitting mixed effect models and exploring group level variation is very easy within the R language
and ecosystem. In future tutorials we will explore comparing across models, doing inference with
mixed-effect models, and creating graphical representations of mixed effect models to understand
their effects.
Consider subscribing to our newsletter, the Civic Pulse
, for monthly emails about how data skills like these are being practiced in social policy.
]]>
{
"attach_link": true,
"format_string": "{{title}}\n\n{{summary}}",
"og_description": "Update: Since this post was released I have co-authored an R package to make some of the items in this post easier to do. This package is called merTools and is available on CRAN and on GitHub. To read more about it, read my new post h ere and check out the package on GitHub . Introduction # Analysts dealing with grouped data and complex hierarchical structures in their data ranging from measurements nested within participants, to counties nested within states or students nested within classrooms often find themselves in need of modeling tools to reflect this structure of their data. In R there are two predominant ways to fit multilevel models that account for such structure in the data. These tutorials will show the user how to use both the lme4 package in R to fit linear and nonlinear mixed effect models, and to use rstan to fit fully Bayesian multilevel models. The focus here will be on how to fit the models in R and not the theory behind the models. For background on multilevel modeling, see the references. [1]",
"og_image": "https://jaredknowles.com/og/posts/getting-started-with-mixed-effect-models-in-r.png",
"og_title": "Getting Started with Mixed Effect Models in R"
}
Latent Variable Analysis with R: Getting Setup with lavaanhttps://jaredknowles.com/posts/latent-variable-analysis-with-r-getting-setup-with-lavaan/2013-09-01T22:23:00Z2013-09-01T22:23:00ZGetting Started with Structural Equation Modeling Part 1 Getting Started with Structural Equation Modeling: Part 1 # Introduction # For the analyst familiar with linear regression fitting structural equation models can at first feel strange. In the R environment, fitting structural equation models involves learning new modeling syntax, new plotting syntax, and often a new data input method. However, a quick reorientation and soon the user is exposed to the differences, fitting structural equation models can be a powerful tool in the analyst’s toolkit.Getting Started with Structural Equation Modeling Part 1
Getting Started with Structural Equation Modeling: Part 1#
For the analyst familiar with linear regression fitting structural equation models
can at first feel strange. In the R environment, fitting structural equation models
involves learning new modeling syntax, new plotting syntax, and often a new
data input method. However, a quick reorientation and soon the user is exposed
to the differences, fitting structural equation models can be a powerful tool in
the analyst’s toolkit.
This tutorial will cover getting set up and running a few basic models using lavaan
in R.1
Future tutorials will cover:
Getting started using structural equation modeling (SEM) in R can be daunting. There are
lots of different packages for implementing SEM in R and there are different features
of SEM that a user might be interested in implementing. A few packages you might come
across can be found on the CRAN Psychometrics Task View
.
For those who want to just dive in the lavaan package seems to offer the most
comprehensive feature set for most SEM users and has a well thought out and easy
to learn syntax for describing SEM models. To install lavaan, we just run:
# Main versioninstall.packages("lavaan")# Or to install the dev versionlibrary(devtools)install_github("lavaan","yrosseel")
Once we load up the lavaan package, we need to read in the dataset. lavaan accepts
two different types of data, either a standard R dataframe, or a variance-covariance
matrix. Since the latter is unfamiliar to us coming from the standard lm linear modeling
framework in R, we’ll start with reading in the simplest variance-covariance matrix
possible and running a path analysis model.
# Note that we only input the lower triangle of the matrix. This is# sufficient though we could put the whole matrix in if we like
Now we have a variance-covariance matrix in our environment named mat1 and a
variable myN corresponding to the number of observations in our dataset. Alternatively,
we could provide R with the full dataset and it can derive mat1 and myN itself.
With this data we can construct two possible models:
Depression (DEP) influences Immune System (IMM) influences Illness (ILL)
IMM influences ILL influences DEP
Using SEM we can evaluate which model best explains the covariances we observe in
our data above. Fitting models in lavaan is a two step process. First, we create
a text string that serves as the lavaan model and follows the lavaanmodel
syntax
. Next, we
give lavaan the instructions on how to fit this model to the data using either the
cfa, lavaan, or sem functions. Here we will use the sem function. Other
functions will be covered in a future post.
# Specify the modelmod1<-"ILL ~ IMM \n IMM ~ DEP"# Give lavaan the command to fit the modelmod1fit<-sem(mod1,sample.cov=mat1,sample.nobs=500)# Specify model 2mod2<-"DEP ~ ILL\n ILL ~ IMM"mod2fit<-sem(mod2,sample.cov=mat1,sample.nobs=500)
Now we have two objects stored in our environment for each model. We have the
model string and the modelfit object. The model fit objects (mod1fit and mod2fit)
are lavaan class objects. These are S4 objects with many supported methods, including
the summary method which provides a lot of useful output:
# Summarize the model fitsummary(mod1fit)## lavaan (0.5-14) converged normally after 12 iterations## ## Number of observations 500## ## Estimator ML## Minimum Function Test Statistic 2.994## Degrees of freedom 1## P-value (Chi-square) 0.084## ## Parameter estimates:## ## Information Expected## Standard Errors Standard## ## Estimate Std.err Z-value P(>|z|)## Regressions:## ILL ~## IMM 0.600 0.036 16.771 0.000## IMM ~## DEP 0.630 0.035 18.140 0.000## ## Variances:## ILL 0.639 0.040## IMM 0.602 0.038
summary(mod2fit)## lavaan (0.5-14) converged normally after 11 iterations## ## Number of observations 500## ## Estimator ML## Minimum Function Test Statistic 198.180## Degrees of freedom 1## P-value (Chi-square) 0.000## ## Parameter estimates:## ## Information Expected## Standard Errors Standard## ## Estimate Std.err Z-value P(>|z|)## Regressions:## DEP ~## ILL 0.330 0.042 7.817 0.000## ILL ~## IMM 0.600 0.036 16.771 0.000## ## Variances:## DEP 0.889 0.056## ILL 0.639 0.040
One of the best ways to understand an SEM model is to inspect the model visually
using a path diagram. Thanks to the semPlot package,
this is easy to do in R.2
First, install semPlot:
# Official versioninstall.packages("semPlot")# Or to install the dev versionlibrary(devtools)install_github("semPlot","SachaEpskamp")
Next we load the library and make some path diagrams.
We can see that very clearly we prefer Model 2. Let’s look at some properties of
model 2 that we can access through the lavaan object with convenience functions.
# Estimates of the model parametersparameterEstimates(mod2fit,ci=TRUE,boot.ci.type="norm")## lhs op rhs est se z pvalue ci.lower ci.upper## 1 DEP ~ ILL 0.330 0.042 7.817 0 0.247 0.413## 2 ILL ~ IMM 0.600 0.036 16.771 0 0.530 0.670## 3 DEP ~~ DEP 0.889 0.056 15.811 0 0.779 1.000## 4 ILL ~~ ILL 0.639 0.040 15.811 0 0.560 0.718## 5 IMM ~~ IMM 0.998 0.000 NA NA 0.998 0.998
# Modification indicesmodindices(mod2fit,standardized=TRUE)## lhs op rhs mi epc sepc.lv sepc.all sepc.nox## 1 DEP ~~ DEP 0.0 0.000 0.000 0.000 0.000## 2 DEP ~~ ILL 163.6 -0.719 -0.719 -0.720 -0.720## 3 DEP ~~ IMM 163.6 0.674 0.674 0.675 0.674## 4 ILL ~~ ILL 0.0 0.000 0.000 0.000 0.000## 5 ILL ~~ IMM NA NA NA NA NA## 6 IMM ~~ IMM 0.0 0.000 0.000 0.000 0.000## 7 DEP ~ ILL 0.0 0.000 0.000 0.000 0.000## 8 DEP ~ IMM 163.6 0.675 0.675 0.675 0.676## 9 ILL ~ DEP 163.6 -0.808 -0.808 -0.808 -0.808## 10 ILL ~ IMM 0.0 0.000 0.000 0.000 0.000## 11 IMM ~ DEP 143.8 0.666 0.666 0.666 0.666## 12 IMM ~ ILL 0.0 0.000 0.000 0.000 0.000
That’s it. From inputing a variance-covariance matrix to fitting a model,
drawing a path diagram, comparing to alternate models, and finally inspecting
the parameters of the preferred model. lavaan is an amazing project which
adds great capabilities to R. These will be explored in future posts.
citation(package="lavaan")## ## To cite lavaan in publications use:## ## Yves Rosseel (2012). lavaan: An R Package for Structural## Equation Modeling. Journal of Statistical Software, 48(2), 1-36.## URL http://www.jstatsoft.org/v48/i02/.## ## A BibTeX entry for LaTeX users is## ## @Article{,## title = {{lavaan}: An {R} Package for Structural Equation Modeling},## author = {Yves Rosseel},## journal = {Journal of Statistical Software},## year = {2012},## volume = {48},## number = {2},## pages = {1--36},## url = {http://www.jstatsoft.org/v48/i02/},## }
citation(package="semPlot")## ## To cite package 'semPlot' in publications use:## ## Sacha Epskamp (2013). semPlot: Path diagrams and visual analysis## of various SEM packages' output. R package version 0.3.3.## https://github.com/SachaEpskamp/semPlot## ## A BibTeX entry for LaTeX users is## ## @Manual{,## title = {semPlot: Path diagrams and visual analysis of various SEM packages' output},## author = {Sacha Epskamp},## year = {2013},## note = {R package version 0.3.3},## url = {https://github.com/SachaEpskamp/semPlot},## }## ## ATTENTION: This citation information has been auto-generated from## the package DESCRIPTION file and may need manual editing, see## 'help("citation")'.
]]>
{
"attach_link": true,
"format_string": "{{title}}\n\n{{summary}}",
"og_description": "Getting Started with Structural Equation Modeling Part 1 Getting Started with Structural Equation Modeling: Part 1 # Introduction # For the analyst familiar with linear regression fitting structural equation models can at first feel strange. In the R environment, fitting structural equation models involves learning new modeling syntax, new plotting syntax, and often a new data input method. However, a quick reorientation and soon the user is exposed to the differences, fitting structural equation models can be a powerful tool in the analyst’s toolkit.",
"og_image": "https://jaredknowles.com/og/posts/latent-variable-analysis-with-r-getting-setup-with-lavaan.png",
"og_title": "Latent Variable Analysis with R: Getting Setup with lavaan"
}
Writing a Minimal Working Example (MWE) in Rhttps://jaredknowles.com/posts/writing-a-minimal-working-example-mwe-in-r/2013-05-27T22:26:22Z2013-05-27T22:26:22ZHow to Ask for Help using R How to Ask for Help using R # The key to getting good help with an R problem is to provide a minimally working reproducible example (MWRE). Making an MWRE is really easy with R, and it will help ensure that those helping you can identify the source of the error, and ideally submit to you back the corrected code to fix the error instead of sending you hunting for code that works. To have an MWRE you need the following items:How to Ask for Help using R
The key to getting good help with an R problem is to provide a minimally working
reproducible example (MWRE). Making an MWRE is really easy with R, and it will
help ensure that those helping you can identify the source of the error, and
ideally submit to you back the corrected code to fix the error instead of sending
you hunting for code that works. To have an MWRE you need the following items:
a minimal dataset that produces the error
the minimal runnable code necessary to produce the data, run on the dataset
provided
the necessary information on the used packages, R version, and system
a seed value, if random properties are part of the code
Let’s look at the tools available in R to help us create each of these components
quickly and easily.
This option works great for a problem where you know you are having trouble with
a command in R. It is not a great option if you are having trouble understanding
why a command you are familiar with won’t work on your data.
Note that for education data that is fairly “realistic”, there are built in
simulated datasets in the eeptools package, created by Jared Knowles.
Inputing data into R and sharing it back out with others is really easy. Part of
the power of R is the ability to create diverse data structures very easily.
Let’s create a simulated data frame of student test scores and demographics.
And, just like that, we have simulated student data. This is a great way to
evaluate problems with plotting data or with large datasets, since we can ask
R to generate a random dataset that is incredibly large if necessary. However,
let’s look at the relationship among our variables using a quick plot:
It looks like race is pretty evenly distributed and there is no relationship
among mathSS and readSS. For some applications this data is sufficient, but
for others we may wish for data that is more realistic.
Sometimes you just want to show others the data you are using and see why
the problem won’t work. The best practice here is to make a subset of the data
you are working on, and then output it using the dput command.
The resulting code can be copied and pasted into an R terminal and it will
automatically build the dataset up exactly as described. Note, that in the above
example, it might have been better if I first cut out all the unnecessary
variables for my problem before I executed the dput command. The goal is to
make the data only necessary to reproduce your code available.
Also, note, that we never send student level data from LDS over e-mail
as this is unsecure. For work on student level data, it is better to either
simulate the data or to use the built in simulated data from the eeptools
package to run your examples.
It may also be the case that you want to dput your data, but you want to keep
the contents of your data anonymous. A Google search came up with a decent
looking function to carry this out:
Once we have our minimal dataset, we need to reproduce our error on that dataset.
This part is critical. If the error goes away when you apply your code to the
minimal dataset, then it will be very hard for others to diagnose the problem
remotely, and it might be time to get some “at your desk” help.
Let’s look at an example where we have an error aggregating data. Let’s assume
I am creating a new data frame for my example, and trying to aggregate that data
by race.
Why do I get an error? Well, if you sent the above code to someone, they could
quickly evaluate it for errors, and look at the mistake if they knew you were
attempting to use the data.table package.
However, they might not know this, so we need to provide one final piece of
information. This is known was the sessionInfo for our R session. To diagnose
the error it is necessary to know what system you are running on, what packages
are loaded in your workspace, and what version of R and a given package you are
using.
Thankfully, R makes this incredibly easy. Just tack on the output from the
sessionInfo() function. This is easy enough to copy and paste or include in
a knitr document.
]]>
{
"attach_link": true,
"format_string": "{{title}}\n\n{{summary}}",
"og_description": "How to Ask for Help using R How to Ask for Help using R # The key to getting good help with an R problem is to provide a minimally working reproducible example (MWRE). Making an MWRE is really easy with R, and it will help ensure that those helping you can identify the source of the error, and ideally submit to you back the corrected code to fix the error instead of sending you hunting for code that works. To have an MWRE you need the following items:",
"og_image": "https://jaredknowles.com/og/posts/writing-a-minimal-working-example-mwe-in-r.png",
"og_title": "Writing a Minimal Working Example (MWE) in R"
}
Announcing eeptools 0.2https://jaredknowles.com/posts/announcing-eeptools-02/2013-04-05T01:10:00Z2013-04-05T01:10:00ZMy R package eeptools has reached version 0.2. As with the last release, this is still a preliminary release which means that functionality is not full, function names and code behavior may still change from version to version, and I am still looking for suggestions and ideas to improve the package – check it out on GitHub . Below, here are the changes in the new version: eeptools 0.2 +++++++++++++++++++++++++++++ New functions for building maps with shapefiles including mapmerge to merge a dataframe and a shapefile, and ggmapmerge to conver this to a document for making a map in ggplot2 statamode updated to allow for multiple methods for handling multiple modes remove_stars deleted and replaced with remove_char to allow for users to specify an arbitrary character string to be removed New plotForWord function to export plots in a Windows MetaFile for inclusion in Microsoft Office documents New age_calc function to allow calculating the age of a vector of birthdates relative to the current date Fix typos in documentation Fix startup message behavior Remove dependencies of the package dramatically so loading is faster and more lightweightMy R package eeptools
has reached version 0.2. As with the last release, this is still a preliminary release which means that functionality is not full, function names and code behavior may still change from version to version, and I am still looking for suggestions and ideas to improve the package – check it out on GitHub
. Below, here are the changes in the new version:
eeptools 0.2
+++++++++++++++++++++++++++++
New functions for building maps with shapefiles including mapmerge to merge a dataframe and a shapefile, and ggmapmerge to conver this to a document for making a map in ggplot2
statamode updated to allow for multiple methods for handling multiple modes
remove_stars deleted and replaced with remove_char to allow for users to specify an arbitrary character string to be removed
New plotForWord function to export plots in a Windows MetaFile for inclusion in Microsoft Office documents
New age_calc function to allow calculating the age of a vector of birthdates relative to the current date
Fix typos in documentation
Fix startup message behavior
Remove dependencies of the package dramatically so loading is faster and more lightweight
]]>
{
"attach_link": true,
"format_string": "{{title}}\n\n{{summary}}",
"og_description": "My R package eeptools has reached version 0.2. As with the last release, this is still a preliminary release which means that functionality is not full, function names and code behavior may still change from version to version, and I am still looking for suggestions and ideas to improve the package – check it out on GitHub . Below, here are the changes in the new version: eeptools 0.2 +++++++++++++++++++++++++++++ New functions for building maps with shapefiles including mapmerge to merge a dataframe and a shapefile, and ggmapmerge to conver this to a document for making a map in ggplot2 statamode updated to allow for multiple methods for handling multiple modes remove_stars deleted and replaced with remove_char to allow for users to specify an arbitrary character string to be removed New plotForWord function to export plots in a Windows MetaFile for inclusion in Microsoft Office documents New age_calc function to allow calculating the age of a vector of birthdates relative to the current date Fix typos in documentation Fix startup message behavior Remove dependencies of the package dramatically so loading is faster and more lightweight",
"og_image": "https://jaredknowles.com/og/posts/announcing-eeptools-02.png",
"og_title": "Announcing eeptools 0.2"
}
Tips and Tricks for HTML and Rhttps://jaredknowles.com/posts/tips-and-tricks-for-html-and-r/2013-03-04T02:43:02Z2013-03-04T02:43:02ZOver the past two months I have tried to convert completely to HTML5 slides , HTML reports and R + knitr . The switch from Sweave came with a few frustrations but I think overall it is way better - it is incredibly efficient and while some flexibility on report style is given up, a lot of speed is gained. To help make the change smoother, I have found that a a few pieces of non-R code have really helped me make HTML reports have parity with what I was doing before in R. An example is the CSS header below.Over the past two months I have tried to convert completely to HTML5 slides
, HTML reports and R + knitr
. The switch from Sweave came with a few frustrations but I think overall it is way better - it is incredibly efficient and while some flexibility on report style is given up, a lot of speed is gained. To help make the change smoother, I have found that a a few pieces of non-R code have really helped me make HTML reports have parity with what I was doing before in R. An example is the CSS header below.
<styletype="text/css">body,td{font-size:16px;font-family:Times;}code.r{font-size:10px;}pre{font-size:10px;font-family:'DejaVu Sans Mono','Droid Sans Mono','Lucida Console',Consolas,Monaco,monospace;}precode{font-size:10px;font-family:'DejaVu Sans Mono','Droid Sans Mono','Lucida Console',Consolas,Monaco,monospace;}code{font-size:16px;font-family:Times;}</style>
By inserting this at the head of our .Rmd file, we can modify a number of style elements in the resulting output. Most importantly, we can modify font sizes.
We can modify the body of our HTML and the font using the first argument. We can modify the appearance of our R code by modifying the second code.r style.
These modifications are really helpful for customizing the look and feel of an HTML file you might want to share for publication or align with your own internal style sheet at your organization. You also might want to increase font sizes if you are converting your .Rmd file to HTML5 slides as well.
]]>
{
"attach_link": true,
"format_string": "{{title}}\n\n{{summary}}",
"og_description": "Over the past two months I have tried to convert completely to HTML5 slides , HTML reports and R + knitr . The switch from Sweave came with a few frustrations but I think overall it is way better - it is incredibly efficient and while some flexibility on report style is given up, a lot of speed is gained. To help make the change smoother, I have found that a a few pieces of non-R code have really helped me make HTML reports have parity with what I was doing before in R. An example is the CSS header below.",
"og_image": "https://jaredknowles.com/og/posts/tips-and-tricks-for-html-and-r.png",
"og_title": "Tips and Tricks for HTML and R"
}
R Bootcamp Materials!https://jaredknowles.com/posts/r-bootcamp-materials/2013-02-25T05:08:27Z2013-02-25T05:08:27ZView fullsize Learn about ColoRs in R! View fullsize Analyze model results with custom functions. View fullsize Good and Bad Graphics To train new employees at the Wisconsin Department of Public Instruction, I have developed a 2-3 day series of training modules on how to get work done in R. These modules cover everything from setting up and installing R and RStudio to creating reproducible analyses using the knitr package. There are also some experimental modules for introductions to basic computer programming, and a refresher course on statistics. I hope to improve both of these over time.View fullsize
Learn about ColoRs in R!
View fullsize
Analyze model results with custom functions.
View fullsize
Good and Bad Graphics
To train new employees at the Wisconsin Department of Public Instruction, I have developed a 2-3 day series of training modules on how to get work done in R. These modules cover everything from setting up and installing R and RStudio to creating reproducible analyses using the knitr
package. There are also some experimental modules for introductions to basic computer programming, and a refresher course on statistics. I hope to improve both of these over time.
I am happy to announce that all of these materials are available online, for free.
The bootcamp covers the following topics:
Introduction to R : History of R, R as a programming language, and features of R.
**Getting Data In :** How to import data into R, manipulate, and manage multiple data objects.
**Sorting and Reshaping Data :**Long to wide, wide to long, and everything in between!
Cleaning Education Data : Includes material from the Strategic Data Project about how to implement common business rules in processing administrative data.
Regression and Basic Analytics in R : Using school mean test scores to do OLS regression and regression diagnostics – a real world example.
**Visualizing Data :**Harness the power of R’s data visualization packages to make compelling and informative visualizations.
**Exporting Your Work :**Learn the knitr package, and how to export graphics, and create PDF reports.
**Advanced Topics :** A potpourri of advanced features in R (by request)
**Programming Principles :**Tips and pointers about writing code. (Needs work)
The best part is, all of the materials are available online and free of charge! (Check out the R Bootcamp page
). They are constantly evolving. We have done two R Bootcamps so far, and hope to do more. Each time the materials get a little better.
For those not ready for a full 2 to 3 day training, together with a colleague at wor (Justin Meyer of RProgramming.net
) we have created a 2-3 hour introduction that is also available on the webpage.
And, of course, all the materials are online on GitHub
. Look for future blog posts on tips for running an R bootcamp and some practical advice. For now, enjoy the materials, and feel free to leave a comment here for feedback, fork the GitHub repo, make a pull request, or take and adopt the materials however you see fit! One parting piece of advice though – don’t wait until day two for the data visualization module – give them the ggplot2 goodness ASAP.
]]>
{
"attach_link": true,
"format_string": "{{title}}\n\n{{summary}}",
"og_description": "View fullsize Learn about ColoRs in R! View fullsize Analyze model results with custom functions. View fullsize Good and Bad Graphics To train new employees at the Wisconsin Department of Public Instruction, I have developed a 2-3 day series of training modules on how to get work done in R. These modules cover everything from setting up and installing R and RStudio to creating reproducible analyses using the knitr package. There are also some experimental modules for introductions to basic computer programming, and a refresher course on statistics. I hope to improve both of these over time.",
"og_image": "https://jaredknowles.com/og/posts/r-bootcamp-materials.png",
"og_title": "R Bootcamp Materials!"
}